HelloWorld
第一个程序:打印输出HelloWorld
1 2 3 4 5 6 7 #include <iostream> int main () std::cout << "Hello World!!" << std::endl; }
#include:引用头文件main:程序的入口(主函数),一个项目只能有一个主函数std:已经定义的命名空间,可释放注释,省略std1 cout << "Hello World!!" << endl;
cout:C++中的输出类endl:换行函数,可以释放缓存区
注释 单行注释
以两个斜线//开始,斜线之后的内容都是注释的内容,不会被编译
多行注释
以/*开始,以*/结束,中间的所有内容都是注释的内容,可以换行,内容不会被编译1 2 3 4 5 6 7 8 9 10 #include <iostream> using namespace std;int main () std::cout << "Hello World!!" << std::endl; }
标识符
标识符:是由字母,数字,下划线,组成的一个字符序列,用来表示程序中的数据
1 2 3 x = 10 y = 20 x + y = 30
标识符的命名规范
由字母,数字,下划线组成,不能有其他的组成部分
不能以数字开头,需要以字母或者下划线组成
不能与系统关键字重复
区分大小写
数据类型 整型
整型:就是整数的类型,描述的是整数数字
数据类型
关键字
空间大小
数据范围
短整型
short
2字节
[2^-15,2^15-1]
整型
int
4字节
[2^-31,2^31-1]
长整型
long
windows:4字节
[2^-31,2^31-1]
长长整型
long long
8字节
[2^-63,2^63-1]
sizeof():返回一个数据类型或者一个变量的空间占用大小1 2 3 4 5 6 int main () int a = 10 ; cout << sizeof (a) << endl; cout << sizeof (int ) << endl; return 0 ; }
浮点型
浮点型:就是小数的类型,用来描述的是小数数字
数据类型
关键字
空间大小
精确范围
单精度浮点型
float
4字节
小数点后面7位
双精度浮点型
double
8字节
小数点后面15位
布尔型
用来描述非真即假,非假及真的数据类型
数据类型
关键字
空间大小
值
布尔型
bool
1字节
true | false
字符型
用来描述一个文本内容中最小组成单位
数据类型
关键字
空间大小
值
字符型
char
1字节
单引号''引起来的内容
字符串型
由若干个字符组成的一个有序的字符序列
数据类型
关键字
空间大小
值
字符串型
std::string
单引号""引起来的内容
变量和常量 变量
变化的量,可以修改值
定义变量的语法:
数据类型 标识符(变量名)数据类型 标识符 = 值数据类型 标识符1[= 值],标识符2[= 值],标识符3[= 值]…
1 2 3 4 5 6 7 8 9 int a;short b = 10 ;long c = 20 ;long long d = 30 ;float e = 3.14 ;double f = 3.1415926 ;bool g = true ;char h = 'a' ;std::string i = "Hello World" ;
常量
不变化的量,不可以修改值
定义常量的语法:const 数据类型 标识符(变量名)
转义字符
转义字符\
配合某些特殊字符使用,使其变成普通字符1 std::string str = "Hello \" World" ;
配合某些特定的普通字符使用,代表某些特殊含义
\t:制表符 tab 四个空格\n:换行符\r:回车符
控制台输入
cin:读取控制台上输入的内容,并且给某一个变量进行赋值
1 2 int num = 0 ;std::cin >> num;
1 2 3 4 5 6 7 8 9 10 11 int n1 = 0 ,n2 = 0 ,n3 = 0 ;std::cin >> n1; std::cin >> n2; std::cin >> n3; std::cout << "n1 = " << n1 << ",n2 = " << n2 << ",n3 = " << n3;
缓冲区问题:缓冲区中,cin从缓冲区取数据给变量进行赋值.和空格会被忽略,可使用cin.ignore()来忽略缓冲区的内容
1 2 3 4 5 6 7 8 9 10 #include <iostream> #include <limits> using namespace std;int main () int num = 0 ,num2 = 0 ,num3 = 0 ; cin.ignore (); cin.ignore (numeric_limits<std::streamsize>::max (),"\n" ); cin >> num; }
可以连续输入
1 2 3 4 5 int main () int num1=0 ,num2=0 ,num3=0 ; cin >> num1 >> num2 >> num3; cout << num1 << num2 << num3 << endl; }
错误处理
cin内部会维护一个状态,来记录本次的读取操作是否正常
cin.good();cin读取状态正确 值为1,否则为0
cin.fail():cin读取状态错误 值为1,否则为0
如果被标记为fail状态,则会影响后续的读取操作
cin.clear():恢复状态,清除错误状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <limits> int main () int num1 = 0 ; cout << "请输入一个整型的数字:" ; cin >> num1; cout << "num1 = " << num1 << endl; cout << "good = " << cin.good () << endl; cout << "fail = " << cin.fail () << endl; cin.clear () cin.ignore (numeric_limits<std::streamsize>::max (),"\n" ); int num1 = 0 ; cout << "请输入一个整型的数字:" ; cin >> num1; cout << "num1 = " << num1 << endl; }
宏定义
宏定义:在文件的头部,使用#define来定义一个标识符,用来描述一个字符串,这个字符串就成为宏定义,使用时会自动替换为定义的值
1 2 3 4 5 6 7 8 #include <iostream> #define SUCCESS_CODE 1 int main () std::cout << SUCCESS_CODE; return 0 ; }
命名空间
为了避免各种类库的命名的标识符冲突,C++引入了关键字namespace(命名空间/名字空间/名称空间),可以更好的控制标识符的作用域
使用语法
定义:namespace 命名空间名{ … };命名空间名::成员名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 #include <iostream> namespace A { int numA = 10 ; void function () namespace AA { int numAA = 20 ; } } namespace B{ int numB = 30 ; } int main () std::cout << A::numA << std::endl; std::cout << A::AA::numAA << std::endl; }
命名空间是开放的,可以随时向一个命名空间添加成员
1 2 3 4 5 6 7 8 9 10 11 namespace A{ int a1 = 10 ; } namespace A{ int a2 = 20 ; } int main () std::cout << A::a2 << std::endl; }
using关键字
直接引用指定的命名空间 或指定空间的指定成员
导入命名空间:using namespace 命名空间
导入命名空间的成员:using 命名空间::成员
1 2 3 4 5 int main () using namespace A; using A::numA; std::cout << numA << std::endl; }
注意事项:
如果引用的命名空间存在和当前的命名空间相同的成员,默认使用当前的命名空间中的成员
如果引用的多个命名空间中存在相同名字的成员,且当前命名空间中没有这个成员,此时出现二义性。命名空间不能省略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 namespace constant1{ const int MAX_SCORE = 100 ; } namespace constant2{ const int MAX_SCORE = 150 ; } int main () const int MAX_SCORE = 200 ; std::cout << MAX_SCORE << std::endl; using namespace constant1; std::cout << MAX_SCORE << std::endl; std::cout << constant1::MAX_SCORE << std::endl; } int main () using namespace constant1; using namespace constant2; std::cout << MAX_SCORE << std::endl; std::cout << constant1::MAX_SCORE << std::endl; std::cout << constant2::MAX_SCORE << std::endl; }
运算符 算术运算符
对数字类型(整型,浮点型,字符型)的数据进行运算
运算符
含义
示例
+
对两个数字进行相加的计算
10 + 3 = 13
-
对两个数字进行相减的计算
10 - 3 = 7
*
对两个数字进行相乘的计算
10 * 3 = 30
/
对两个数字进行相除的计算
10 / 3 = 3
%
对两个数字进行求模的计算(求余数)
10 % 3 = 1
++x
前自增:x先进行+1,再进行运算
y = ++x;x = x+1,y = x + 1
x++
后自增:再进行运算,x先进行+1
y = x++;y = x,x = x + 1
–x
前自减:x先进行-1,再进行运算
y = –x;x = x-1,y = x - 1
x–
后自增:再进行运算,x先进行-1
y = x–;y = x,x = x - 1
注意事项:
整型与整型计算的结果,还是一个整型,所以如果10/3,得到的结果是浮点型3.33333,此时系统会将这个数字强制类型转换成整型的结果,舍去小数点后面的所有数字 ,只保留整数部分3
在进行计算的时候,结果会进行类型提升,将结果提升为取值氛围大的数据类型
int 与 int 的计算结果是 int
int 与 long 的计算结果是 long
float 与 long 的计算结果是 float
float 与 double 的计算结果是 double
1 2 3 4 5 6 7 8 9 int main () int y = 0 ,x = 0 ; y = x++; std::cout << "y = " << y << ";x = " << x << std::endl; int y = 0 ,x = 0 ; y = ++x; std::cout << "y = " << y << ";x = " << x << std::endl; }
赋值运算符
将等号=右边的值赋给左边的变量
运算符
示例
运算结果
=
num = 10
(num = 10) => 10
+=
num += 10
num = (int)(num +10)
-=
num -= 10
num = (int)(num -10)
*=
num *= 10
num = (int)(num *10)
/=
num /= 10
num = (int)(num /10)
%=
num %= 10
num = (int)(num %10)
关系运算符
对两个变量进行大小关系的比较,最后比较的结果一定是布尔类型的
运算符
示例
运算结果
<
10 < 20
true
>
10 > 20
false
<=
10 <= 20
true
>=
10 >= 20
false
==
10 == 20
false
!=
10 != 20
true
逻辑运算符
对两个布尔类型的变量进行的逻辑操作
运算符
描述
示例
&
与运算,两边为真即为真,任意一个为假,结果即为假
true & true => true
|
或运算,两边为假即为假,任意一个为真,结果即为真
true | false => true
!
非运算,非真即假,非假及真
!true => false
^
异或运算,相同为假,不同为真
true ^ true => false
&&
短路与,左边的结果为假,右边的表达式不参与运算
false && true => true
||
短路或,左边的结果为真,右边的表达式不参与运算
true || false => true
位运算符
作用于两个整数数字的运算,将参与运算的每一个数字计算出补码,对补码中的每一位进行类似于逻辑运算的操作,1相当于True,0相当于False
原码:十进制数据的二进制表现形式,最左边为符号位,0为正,1为负
反码:正数的反码是本身,负数的反码在原码的基础上,符号位不变。数值取反,0变1,1变0
补码:正数的补码是本身,负数的补码在反码的基础上+1
运算符
描述
示例
&
位与运算
10 & 20
|
位或运算
10 & 20
^
位异或运算
10 & 20
~
按位取反运算
~10
<<
位左移运算
10 << 1 => 10 * 2
>>
位右移运算
10 >> 1 => 10 / 2
三目运算符
语法:condition(条件) ? value1 : value2condition:是一个bool类型的变量或者bool类型运算结果的表达式condition的值是true,三目运算符的结果取value1,否则取value2
1 2 3 4 int main () int age = 22 ; std::cout << (age >= 18 ? "已成年" : "未成年" ) << std::endl; }
流程控制 顺序结构
代码从上往下,依次执行
1 2 3 4 5 6 7 int main () std::cout << 10 << std::endl; std::cout << 20 << std::endl; std::cout << 30 << std::endl; std::cout << 40 << std::endl; }
分支结构
程序在某一个节点遇到了多种执行的可能性,根据条件,选择一个分支继续执行
if-else
if else 语句:可用于变量的区间范围进行判断,根据结果选择分支继续执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if (条件判断1 true or false ){ } else if (条件判断1 true or false ) { } else { }.... if (条件判断1 true or false ) else if (条件判断1 true or false ) else ....
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int main () int age = 22 ; if ( age >= 16 && age <= 18 ){ std::cout << "青少年" << std::endl; } else if ( age >18 ){ std::cout << "成年人" << std::endl; } else { std::cout << "年龄错误!!" << std::endl; } } ---------------------------------------------- int main () int age = 22 ; if ( age >= 16 && age <= 18 ) std::cout << "青少年" << std::endl; else if ( age >18 ) std::cout << "成年人" << std::endl; else std::cout << "年龄错误!!" << std::endl; }
switch-case
switch case语句:用于多重分支且条件判断是等值(固定特定值)判断的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 int main () switch (variable){ case const1: break ; case const1: break ; default : break ; } }
variable:确定的字符或整数值
case:值只能是字符或整数的字面量,不能是变量,值不允许重复
break:表示跳出/结束,结束switch语句
default:所有情况都不匹配,执行该处的内容,可以写在任意位置,也可以省略不写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #include <iostream> using namespace std;int main () int month = 123 ; switch (month) { case 123 : cout << "春天" << endl; break ; case 456 : cout << "夏天" << endl; break ; case 789 : cout << "秋天" << endl; break ; case 101112 : cout << "冬天" << endl; break ; default : cout << "没有该季节!!!" << endl; break ; } return 0 ; }
switch case 语句中的的穿透性:
当switch的变量和某一个case的值匹配上之后,将会跳过后续的case或者default的匹配,直接向后穿透
为了避免switch的穿透性,每一个case和default可以使用break,来跳出switch语句
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> using namespace std;int main () int month = 456 ; switch (month) { case 123 : cout << "春天" << endl; case 456 : cout << "夏天" << endl; case 789 : cout << "秋天" << endl; case 101112 : cout << "冬天" << endl; default : cout << "没有该季节!!!" << endl; } return 0 ; }
当然也可以利用switch的穿透性实现特定的功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;int main () int month = 6 ; switch (month) { case 1 : case 2 : case 3 : cout << "春天" << endl; break ; case 4 : case 5 : case 6 : cout << "夏天" << endl; break ; case 7 : case 8 : case 9 : cout << "秋天" << endl; break ; case 10 : case 11 : case 12 : cout << "冬天" << endl; break ; default : cout << "没有该季节!!!" << endl; break ; } return 0 ; }
循环结构
某段代码需要被重复执行多次并且遵循一定规律,则使用循环结构
while循环
条件表达式:循环终止的判断条件语句,结果为bool类型的表达式
循环体:n行循环要执行的语句
流程说明:
执行条件表达式,也就是执行循环是否终止的判断条件,表达式的值如果是false,则循环结束,如果是true,循环继续执行
执行循环语句,大括号中的代码,需要循环的代码
回到第一步再次执行,直到表达式的结果为false,while循环才会结束
注意事项
while循环本身没有循环变量的声明和初始化的部分,应在while循环前声明循环变量并赋值
while循环本身也没有控制循环终止的判断条件语句部分,所以需要再循环体中增加相应的控制语句,否则容易死循环
1 2 3 4 5 6 7 8 9 int main () int count = 1 ; while (i <= 5 ){ std::cout << i << std::endl; i++; } }
示例:需要在控制台上输入一个整型数字,如果用户在控制台上输入的不正确,让用户重复输入,直到输入正确为止
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> #include <limits> using namespace std;int main () int num = 0 ; cout << "请输入一个整数:" ; cin >> num; while (cin.fail ()){ cout << "输入错误,请重新输入:" ; cin.clear (); cin.ignore (numeric_limits< streamsize >::max (), '\n' ); cin >> num; } cout << "num = " << num << endl; }
do-while循环
流程说明
先执行循环体中的语句
执行条件表达式(循环终止的条件判断语句),结果如果为true,继续执行,如果是false,则循环结束
回到第一步,再次执行,直到条件表达式的结果为false
注意事项
do-while循环为先执行后判断,先执行一次循环体中的代码,然后再执行条件表达式,所以do-while循环至少执行一次
其他特点跟while循环一样
1 2 3 4 5 6 7 8 9 10 int main () int count = 0 ; do { cout << "hello world" << endl; count++; } while (count < 3 ); }
for循环 1 2 3 for (循环起点;循环条件;循环步长){ }
循环起点:循环变量的初始化,如 int i = 0
循环条件:循环终止的条件,为布尔表达式, 如 i < 10
循环步长:循环改变的控制条件语句,如 i++
循环体:循环要执行的语句
表达式之间要用分号;分隔
流程说明
第一步:执行循环变量初始化语句(循环起点)
第二步:执行循环终止的判断条件表达式,结果为ture,继续执行第三步,结果为false,结束循环
第三步:执行循环语句
第四步:执行循环步长,也就是循环改变的控制条件语句,使循环变量的值发生改变
第五步:回到第二步,再次执行执行第二步到第五步,直到第二步的循环条件的表达式结果为false,循环结束
1 2 3 4 5 6 int main () for (int i = 0 ;i < 5 ;i++) { cout << "当前循环变量的值:" << i << endl; } }
for循环的小括号中每一个部分都可以省略不写,但是分号;不能省略
1 2 3 4 5 6 7 int main () int i = 0 ; for ( ; ; ){ cout << i << endl; i++; } }
流程控制的关键字
break:
用于终止某个语句块的执行
如果是在循环中,则是跳出所在的循环,如果是在switch语句中,则为跳出所在的switch语句
1 2 3 4 5 6 7 8 9 int main () for (int i = 1 ;i < 10 ;i++) { if (i == 6 ){ break ; } cout << i << endl; } }
continue:
跳过本次循环,执行下一次循环,(如果有多次循环,默认继续执行离自己最近的循环)提前终止本次循环
只能在循环语句中使用
1 2 3 4 5 6 7 8 9 int main () for (int i = 1 ;i < 10 ;i++) { if (i == 6 ){ continue ; } cout << i << endl; } }
goto:
可以在任意的位置设置标签,使用关键字goto可以直接跳转到指定的标签的位置继续执行
1 2 3 4 5 6 7 8 9 10 11 12 int main () label1: cout << "1" << endl; goto label3; label2: cout << "2" << endl; label3: cout << "3" << endl; }
函数
函数是一个可以多次使用的功能代码块
函数的定义 1 2 3 4 5 6 7 8 返回值类型 函数名(参数列表){ 函数体 return 返回值 } 函数名(参数列表)
返回值:表示函数执行的结果,无返回值为void,有返回值就为对应的数据类型,return返回函数执行后的结果,并结束函数的执行
函数名:遵循标识符的命名规则
参数列表:定义若干个参数的部分,(参数类型 参数名1,参数类型 参数名2,参数类型,参数名3……)
函数体:函数的功能实现部分
1 2 3 4 5 6 7 8 9 10 11 12 int max (int a,int b) if (a > b) return a; else return b; } int main () int result = max (10 ,20 ); cout << result << endl; }
注意事项
函数不能嵌套
函数不调用,函数就不会被执行
函数定义写在main方法前面,但可以提前声明变量名
函数的执行会压到栈中去执行:先进先出,先调用的函数,在栈的底部存放,而新调用的函数,会在栈的顶部存放,程序先处理栈顶的函数中的逻辑
函数的调用:如果函数定义有参数列表,则调用时,参数个数和参数类型必须一致,调用时必须为每个参数赋值
形参:在定义函数的时候,小括号中定义的参数,由于这样的参数只有形式上的定义,并没有具体的值,因此被称为形式
实参:在调用函数的时候,小括号中定义的参数,由于这样的参数,位形参提供了确切的值,因此将这样的参数叫做实际参数
传参:在调用的函数的时候,用实参给形参赋值,这样的过程叫做传参
参数可以使用const来修饰,表示参数的值不允许修改的
在定义函数的时候,可以给参数一个默认值,但该参数要放到参数列表的末尾,传参时可以赋值,也可以不赋值
函数的重载 OverLoad
在一个类中的多个函数,函数名相同,参数列表不同(类型和数量不同),则这两个函数就构成了重载关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int add (int num1,int num2) return num1 + num2; } int add (int num1,int num2,int num3) return num1 + num2 + num3; } int add (int num1,double num2) return num1 + num2; } int main () cout << add (1 ,2 ) << endl; cout << add (1 ,2 ,3 ) << endl; cout << add (1 ,2.3 ) << endl; }
函数的递归
递归:一种程序设计的思想,在解决问题的时候,可以将问题拆分成若干个小问题,这些小问题的解决方式,与大的问题解决方式相同,通过解决这些小问题,逐渐解决这个大问题
由于涉及到方法的循环调用,因此容易出现死递归的情况,即所有的方法调用没有出口,只能将方法压栈执行,但是无法结束方法,因此在使用递归的时候,需要设置有效的出口条件,避免无穷递归
递进:每一次推进,计算都比上一次变得简单,直至简单到无需继续推进,就能获得结果,也叫到达出口
回归:基于出口的结果,逐层向上回归,一次计算每一层的结果,直至回归到最顶层
1 2 3 4 5 6 7 8 9 int multiply (int n) if (n == 1 ) return 1 ; return n * multiply (n - 1 ); } int main () cout << multiply (5 ) << endl; }
1 2 3 4 5 6 7 8 9 int sum (int n) if (n == 1 ) return 1 ; return n + sum (n - 1 ); } int main () cout << sum (3 ) << endl; }
调用其他文件中的函数
.cpp文件中的内容是无法跨文件直接访问的, 若需要让某一个函数跨文件访问,需要为其定义一个.h文件,称为头文件在头文件中添加函数的声明部分即可,需要使用的时候,直接使用#include来包含指定的头文件即可完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int min (int num1,int num2) if (num1 < num2) return num1; else return num2; } int max (int num1,int num2) if (num1 < num2) return num2; else return num1; }
1 2 3 4 int min (int num1,int num2) int max (int num1,int num2)
1 2 3 4 5 6 7 8 9 10 #include <iostream> #include "tools.h" using namespace std;int main () cout << max (10 ,20 ) << endl; cout << min (10 ,20 ) << endl; }
指针与引用 内存分析 内存分区
在程序执行的时候,会在内存中开辟一些空间,存储数据,而内存又可以分为:栈区,堆区,全局区,代码区四个区
代码区
代码区存放程序编译之后生成的二进制代码,例如我们写的函数就是存储在这。PS;函数在程序编译后,存储于代码区,调用函数时,会压到栈区执行其中的代码
全局区
全局区内的变量在程序编译阶段已经分配好内存空间并初始化,这块内存在程序的整个运行期间都会存在,主要存放静态变量,全局变量,全局常量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 using namespace std;int g_num1 = 100 ; const int g_num2 = 100 ; static int g_num3 = 100 ; static const int g_num4 = 100 ; int main () int num1 = 10 ; const int num2 = 10 ; static int mum3 = 10 ; static const int num4 = 10 ; cout << &g_num1 << endl; cout << &g_num2 << endl; cout << &g_num3 << endl; cout << &g_num4 << endl; cout << &num1 << endl; cout << &num2 << endl; cout << &num3 << endl; cout << &num4 << endl; }
栈区
栈区由系统进行的内存管理,主要存放函数的参数以及局部变量,在函数完成执行,系统会自动释放栈区的内存,不需要用户管理
堆区
堆区就是通过new、malloc、realloc分配的内存块,由程序员手动申请,手动释放,若不手动释放,程序结束后由系统回收,生命周期是整个程序执行期间,编译器不会负责它们的释放工作,需要用程序区释放。分配方式类似于数据结构中的链表。“内存泄漏”通常说的就是堆区。
内存中的数据残留
所谓的删除数据,删除的只是你对指定地址范围空间的使用权,你不能够再去使用这块空间了,但是这块空间中原来的内容是不会被删除掉的!
指针
定义变量就是在内存中开辟了一块指定大小的空间,空间开辟的大小取决于不同的数据类型所占用的空间大小。并且可以在这样的空间中进行值的赋值
指针:每一个开辟中的内存空间,都是有一个唯一的地址的,而这样的地址我们就称为是指针
&:取地址操作符,取出变量的内存地址*:间接寻址符:返回变量所指定地址的变量的值
指针的定义
定义:数据类型``* 指针名
1 2 3 4 5 6 7 8 int a;int * pa;pa = &a; printf ("%d" , *pa);
指针的类型
1 2 3 4 5 6 7 8 int main () int * pi; short * ps; long * pl; float * pf; double * pd; char * pc; }
明明都是地址,为什么区分指针类型?因为不同类型的指针±整数所跳过的字节数不同
int*类型的指针 + 1 是跳过四个字节double*类型的指针 + 1 是跳过八个字节char*类型的指针 + 1 是跳过一个字节指针 ± 整数;是指针向前/向后移动的大小(指针指向变量类型大小 * 整数)指针 - 指针:结果是两个指针之间所隔的元素个数,这种操作通常用于计算数组中两个元素之间的距离。
指针的作用就是通过地址取访问指针指向的变量。
指针的类型决定了指针解引用能够访问的字节数。
例如上面的 int*类型的指针能访问四个字节,double*类型的指针可以访问八个字节,char*类型的指针能够访问一个字节
空指针
空指针:指的是没有存储任何内存地址的指针变量,一般使用NULL来表示一个空的地址。通常情况下,使用空指针可以对指针变量进行初始化。
1 2 3 4 5 6 int * p = NULL ; cout << *p << endl;
野指针
野指针:指针中存储有一个内存地址,但是这个地址指向的空间已经不存在了,这样的指针称为野指针
1 2 3 4 int * p = (int *)0x1234 ;cout << *p << endl;
常量指针
const放在*之前,表示常量指针,即常量的指针指针的指向是可以修改的,但是不能通过指针来修改指向空间的值
1 2 3 4 5 6 7 8 int num1 = 100 ;int num2 = 200 ;const int * p1 = &num1;p1 = &num2;
指针常量
const放在*之后,表示指针常量,即指针是一个常量值可以通过指针来修改指向空间的值,但是不能修改指针的地址指向
1 2 3 4 5 6 7 8 int num1 = 100 ;int num2 = 200 ;int * const p2 = &num1;*p2 = 300 ;
1 2 3 4 5 6 7 8 9 10 11 12 13 void interchange (int * n1,int * n2) int temp = *n1; *n1 = *n2; *n2 = temp; } int main () int a = 10 ; int b = 20 ; interchange (&a,&b); cout << "a = " << a << endl; cout << "b = " << b << endl; }
引用
变量名实质上是一段连续内存空间的别名
引用可以作为一个已定义变量的别名,通过这个别名和原来的名字都能够找到这份数据
定义:数据类型 & 引用名
1 2 3 4 5 6 7 int main () int a = 100 ; int & b = a; cout << "a = " << a << endl; cout << "b = " << b << endl; cout << &a == &b << endl; }
注意事项:
&在此不是求地址运算,而是起标识作用类型标识符是指目标变量的类型
引用必须在定义的同时初始化,并且以后也要从一而终,不能再引用其它数据,有点类似于 const变量
引用初始化之后不能改变
不能有NULL引用。必须确保引用是和一块合法的存储单元关联
可以建立对数组的引用
引用的本质
所谓的引用,其实本质来讲就是一个指针常量
1 2 3 4 5 6 7 8 9 10 11 12 13 int main () int n = 10 ; int & a = n; int & rn = n; rn = 200 ; }
常量引用
常量引用,就是对一个常量建立引用,又称为常引用。主要用在函数的形参部分,访问误操作导致在函数题中通过形参,修改实参的值
1 2 3 4 5 void change (const int & n) cout << n << endl; }
数组
数组(array)是一种线性数据结构,其将相同类型的元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的索引(index)相同类型元素的顺序集合
特征:
数组可以用来存储任意数据类型的数据,但是所有的数据需要是相同的数据类型
数组是一个定长的容器,一旦初始化完成,长度将不能改变
数组中的元素被存储在一段连续的内存空间中
元素: 数组中存储的每一个数据,称为数组中的元素长度: 数组的容量,即数组中可以存储多少个元素遍历: 依次获取数组中的每一个元素
数组的定义
数据类型 数组名[数组长度]数据类型 数组名[数组长度] = {元素1,元素2,元素3……}数据类型 数组名[] = {元素1,元素2,元素3……}
1 2 3 4 5 6 7 8 9 int array1[10 ];int array2[10 ] = {1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 }; int array3[10 ] = {1 , 2 , 3 }; int array4[] = {1 , 2 , 3 , 4 , 5 };
数组的使用
数组的访问:序号,称为 下标。我们在访问数组中的元素的时候,通过下标来访问。
注意事项: 数组中元素的下标是从0开始的!即数组中的元素下标范围是 [0, 数组长度-1]
访问:数组名[下标]
修改:数组名[下标] = 值
sizeof():返回一个对象或者类型所占的内存字节数注意事项: 通过下标访问数组元素的时候,注意不要越界!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int array[10 ] = {0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 };cout << array[5 ] << endl; array[5 ] = 50 ; int length = sizeof (array) / sizeof (int );for (int i = 0 ; i < length; i++) { cout << array[i] << endl; }
数组的内存分析
数组是一个容器,在内存中进行空间开辟的时候,并不是一个整体的空间,而是开辟了若干个连续的空间首元素的内存地址!
int arr[10] = {1, 2, 3, 4, 5};
arr表示的是数组中首元素的内存地址。
可以直接通过 *arr 来找到数组中的首元素
后面一个元素,可以通过arr的内存地址+4来访问到,再后面的一个元素,再加一个4….
C++将这一个元素的内存占用空间大小作为一个单位 例如: int数组,一个单位就是4个字节,short数组,一个单位就是2个字节*arr就可以访问*(arr + 1)个单位*(arr + 2)个单位*(arr + 3)个单位
注意事项:当数组作为参数传递到一个函数中的时候,传递的只是首元素的地址!
1 2 3 4 5 6 7 8 9 10 11 int main () int arr[] = {1 ,2 ,3 ,4 ,5 ,6 }; int len = sizeof (arr) / sizeof (int ); cout << len << endl; cout << *arr << endl; cout << *(arr + 1 ) << endl; cout << *(arr + 2 ) << endl; cout << *(arr + 3 ) << endl; cout << *(arr + 4 ) << endl; cout << *(arr + 5 ) << endl; }
1 2 3 4 5 6 7 8 9 10 11 12 13 void printArray1 (int arr[]) int len = sizeof (arr) / sizeof (int ); cout << len << endl; } void printArray2 (int * arr, int len) for (int i = 0 ; i < len; i++) { cout << arr[i] << endl; } }
数组的遍历 下标遍历 1 2 3 4 5 6 7 8 9 int arr[10 ] = {1 , 2 , 3 , 4 , 5 , 6 };int len = sizeof (arr) / sizeof (int );for (int i = 0 ; i < len; i++) { cout << arr[i] << endl; }
范围遍历 1 2 3 4 5 int arr[10 ] = {1 , 2 , 3 , 4 , 5 };for (int ele : arr) { cout << ele << endl; }
数组的排序 选择排序
开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾
设数组的长度为n
初始状态下,所有元素未排序,即未排序(索引)区间为[0,n-1]
选取区间[0,n-1]中的最小元素,将其与索引0处的元素交换。完成后,数组前 1 个元素已排序
选取区间[1,n-1]中的最小元素,将其与索引1处的元素交换。完成后,数组前 2 个元素已排序。
以此类推。经过n-1轮选择与交换后,数组前n-1个元素已排序。
仅剩的一个元素必定是最大元素,无须排序,因此数组排序完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> using namespace std;void selectionSort (int * arr,int len) for (int i = 0 ; i < len - 1 ; i++){ int minIndex = i; for (int j = i + 1 ; j < len; j++){ if (arr[minIndex] > arr[j]){ minIndex = j; } } int temp = arr[i]; arr[i] = arr[minIndex]; arr[minIndex] = temp; } } void printArray (int * arr,int len) cout << "[" ; for (int i = 0 ; i < len; ++i) { if (i != len-1 ) cout << arr[i] << "," ; else cout << arr[i]; } cout << "]" << endl; } int main () int array[10 ] = {1 , 3 , 5 , 7 , 9 , 0 , 8 , 6 , 4 , 2 }; int len = sizeof (array) / sizeof (int ); sort (array, len); printArray (array, len); }
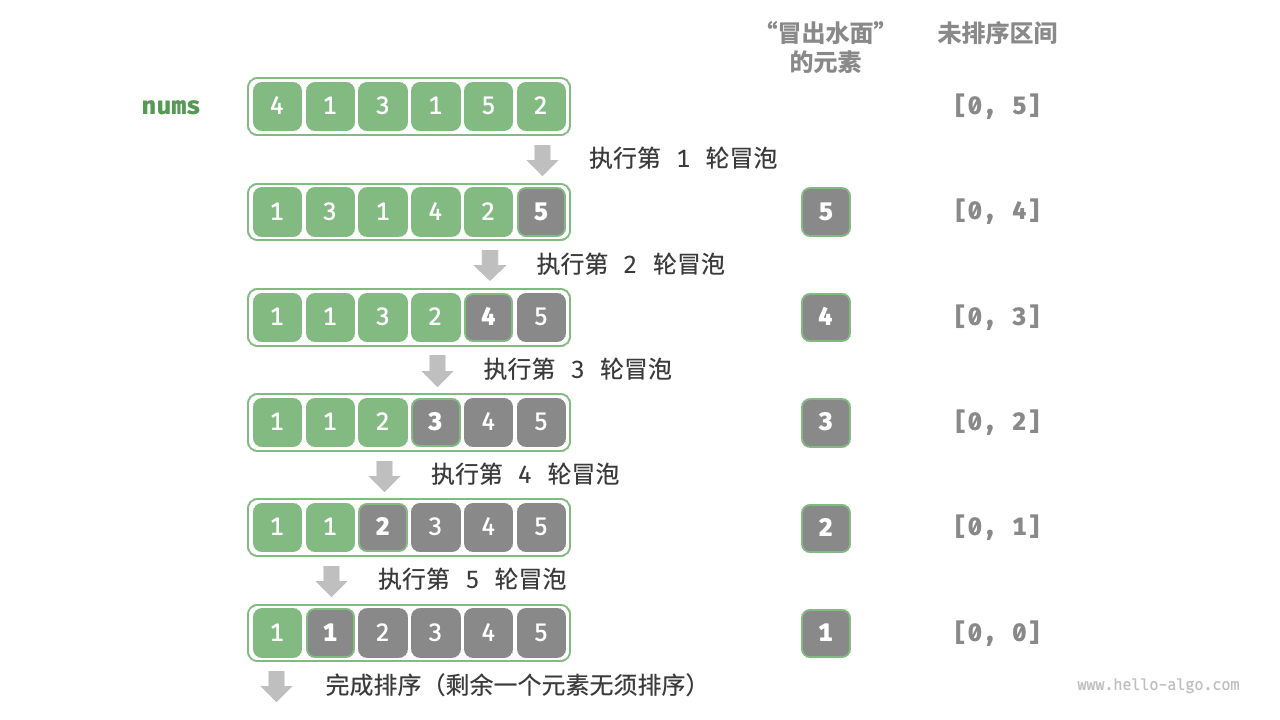
冒泡排序
从数组最左端开始向右遍历,依次比较相邻元素大小 ,如果左元素 > 右元素就交换二者。遍历完成后,最大的元素会被移动到数组的最右端
设数组的长度为n
首先,对n个元素执行冒泡,将数组的最大元素交换至正确位置。
接下来,对剩余n-1个元素执行冒泡,将第二大元素交换至正确位置。
以此类推,经过n-1轮冒泡后,前n-1大的元素都被交换至正确位置。
仅剩的一个元素必定是最小元素,无须排序,因此数组排序完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <iostream> using namespace std;void sort (int * array, int len) for (int i = 0 ; i < len - 1 ; i++) { for (int j = 0 ; j < len - 1 - i; j++) { if (array[j] > array[j + 1 ]) { int temp = array[j]; array[j] = array[j + 1 ]; array[j + 1 ] = tmp; } } } } void printArray (int * arr,int len) cout << "[" ; for (int i = 0 ; i < len; ++i) { if (i != len-1 ) cout << arr[i] << "," ; else cout << arr[i]; } cout << "]" << endl; } int main () int array[10 ] = {1 , 3 , 5 , 7 , 9 , 0 , 8 , 6 , 4 , 2 }; int len = sizeof (array) / sizeof (int ); sort (array, len); printArray (array, len); }
数组元素查找
数组元素查找指的是从给定的一个数组中查询指定元素出现的下标
顺序查询法
顺序查询,就是从前往后遍历数组 ,将数组中的每一个元素和需要查询的元素进行对比。如果比较结果是相同的,说明找到了需要查询的元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 #include <iostream> using namespace std;int indexOf (const int * array, int len, int element) for (int i = 0 ; i < len; i++) { if (array[i] == element) { return i; } } return -1 ; } int main () int array[10 ] = {1 , 3 , 5 , 7 , 9 , 0 , 8 , 6 , 4 , 2 }; int len = sizeof (array) / sizeof (int ); int index = indexOf (array, len, 7 ); cout << index << endl; }
二分查询法
二分查询, 即利用数组中间的位置 , 将数组分为前后两个子表。
如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表
重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功
注意:二分查询, 要求数组必须是排序的, 否则无法使用二分查询
Step 1 Step2 Step3 Step4 Step5 Step6 Step7
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> using namespace std;int indexOf (const int * array, int len, int element) int minIndex = 0 , maxIndex = len - 1 ; while (minIndex <= maxIndex) { int midIndex = (maxIndex + minIndex) / 2 ; if (array[midIndex] > element) { maxIndex = midIndex - 1 ; } else if (array[midIndex] < element) { minIndex = midIndex + 1 ; } else { return midIndex; } } return -1 ; } int main () int array[10 ] = {1 , 3 , 5 , 7 , 9 , 0 , 8 , 6 , 4 , 2 }; int len = sizeof (array) / sizeof (int ); int index = indexOf (array, len, 7 ); cout << index << endl; }
数组的练习
设计一个函数,找出一个数组中最大的数字,连同所在的下标一起输出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void printMaxElementAndIndex (int * array, int len) if (len == 0 ) { cout << "空数组,不存在最大值!" << endl; return ; } int maxElement = array[0 ], maxIndex = 0 ; for (int i = 0 ; i < len; i++) { if (array[i] > maxElement) { maxElement = array[i]; maxIndex = i; } } cout << "最大值是: " << maxElement << ", 所在的下标是: " << maxIndex << endl; }
设计一个函数,判断一个数组是不是一个升序的数组。
1 2 3 4 5 6 7 8 9 bool checkAscending (const int * array, int len) for (int i = 0 ; i < len - 1 ; i++) { if (array[i] > array[i + 1 ]) { return false ; } } return true ; }
1 2 3 4 5 6 7 8 9 bool checkAscending (const int * array, int maxIndex) if (maxIndex == 1 ) { return array[1 ] >= array[0 ]; } return array[maxIndex] >= array[maxIndex - 1 ] && checkAscending (array, maxIndex - 1 ); }
设计一个函数,找出一个整型数组中的第二大的值。
不可以通过排序实现,不能修改数组中的数据顺序
要考虑到最大的数字可能出现多次
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 int getSecondMax (const int * array, int len) if (len <= 1 ) { cout << "没有次大值" << endl; return -1 ; } int max = array[0 ], second = array[0 ]; for (int i = 0 ; i < len; i++) { if (array[i] > max) { second = max; max = array[i]; } else if (array[i] < max && array[i] > second) { second = array[i]; } } return second; }
设计一个函数,将一个数组中的元素倒序排列(注意,不是降序)。
1 2 3 4 5 6 7 8 void reverse (int * array, int len) for (int i = 0 ; i < len / 2 ; i++) { int temp = array[i]; array[i] = array[array.length - 1 - i]; array[array.length - i - 1 ] = temp; } }
将一个数组中的元素拷贝到另外一个数组中。
1 2 3 4 5 6 7 8 9 10 void copy (int * src, int srcLen, int * dst, int dstLen) for (int i = 0 ; i < srcLen; i++) { if (i >= dstLen) { break ; } dst[i] = src[i]; } }
设计一个函数,比较两个数组中的元素是否相同(数量、每一个元素都相同,才认为是相同的数组)。
1 2 3 4 5 6 7 8 9 10 11 12 13 bool equals (int * array1, int arr1Len, int * array2, int arr2Len) if (array1 == NULL || array2 == NULL || arr1Len != arr2Len) { return false ; } for (int i = 0 ; i < arr1Len; i++) { if (array1[i] != array2[i]) { return false ; } } return true ; }
浅拷贝与深拷贝 有时候我们对数组进行操作的时候,需要进行数组的拷贝,而此时会有浅拷贝和深拷贝两种数组的拷贝形式。
浅拷贝:也就是地址拷贝,拷贝到的是数组的首元素地址。
深拷贝:定义一个新的数组,长度与原来的数组相同,将原来数组中的每一个元素依次拷贝到新的数组中 。
从上述的说明中,可以看出,所谓的浅拷贝其实就是拷贝了一个地址,得到的数组与原来的数组指向的其实是同一块空间。因此对一个数组进行的操作都会对另外一个数组产生影响。而深拷贝则不然,深拷贝是创建了一个全新的数组,虽然元素与原来的数组元素相同,但是从内存上来看的话,这是一个全新的数组,修改这个数组不会对另外一个数组产生任何影响。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <iostream> using namespace std;int main () int array[] = {1 , 2 , 3 , 4 , 5 }; int * array_copy_1 = array; int array_copy_deep[5 ]; for (int i = 0 ; i < 5 ; i++) { array_copy_deep[i] = array[i]; } }
二维数组 二维数组的介绍
数组其实就是一个容器,存储着若干的数据。数组中可以存储任意类型的元素,可以存储整数、可以存储浮点数字、可以存储字符串,其实数组中也可以存储一个数组
如果一个数组中存储的元素类型是一个数组,那么这样的数组就是二维数组
理论上讲还有三维数组、四维数组,只不过一般不去讨论。我们在讨论多维数组的时候,基本也就是指的二维数组了。
二维数组的定义 通常我们会将二维数组比作一个行列矩阵,二维数组有多少元素,相当于有多少行。二维数组中的小一维数组有多少元素,相当于有多少列
二维数组的定义:
数据类型 标识符[行数][列数];
数据类型 标识符[行数][列数] = { {val1, val2, val3}, {val1, val2, val3} };
数据类型 标识符[行数][列数] = { val1, val2, val3, val4 };
数据类型 标识符[][列数] = { val1, val2, val3, … };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #include <iostream> using namespace std;int main () int array1[3 ][5 ]; int array2[3 ][5 ] = { {1 , 2 , 3 , 4 , 5 }, {2 , 2 , 3 , 3 , 3 }, {3 , 2 , 1 , 4 , 5 } }; int array3[3 ][5 ] = {1 , 2 , 3 , 4 , 5 , 10 , 20 , 30 , 40 , 50 , 100 , 200 }; int array4[][5 ] = {1 , 2 , 3 , 4 , 5 , 2 , 2 , 3 , 4 , 5 , 1 }; }
二维数组的使用 二维数组中的元素访问与一维数组是相同的,通过下标来进行访问即可!
1 2 3 4 5 6 7 8 int main () int arr[3 ][5 ] = { {1 , 2 , 3 , 4 , 5 }, {2 , 2 , 3 , 3 , 3 }, {3 , 2 , 1 , 4 , 5 } }; cout << arr[2 ][2 ] << endl; }
面向对象 面向对象介绍 面向对象与面向过程
面向过程 是一种看待问题、解决问题的思维方式,着眼点在于问题是如何一步步的解决的 ,然后亲力亲为的解决问题
面向对象 是一种看待问题、解决问题的思维方式,着眼点在于找到一个能够帮助解决问题的实体,然后委托这个实体来解决问题
案例分析 小明买电脑
面向过程
(小明)去市场买配件
(小明)将零件运回家里
(小明)将电脑组装起来
面向对象
找到一个能够帮助买电脑的朋友 – 老王
委托老王去买电脑配件
委托老王把电脑运回来
委托老王把电脑组装起来
把大象装冰箱
面向过程
(我)打开冰箱门
(我)把大象装进冰箱
(我)关上冰箱门
面向对象
冰箱,开门
大象,进去冰箱里
冰箱,关门
类与对象 在面向对象的编程思想中,着眼点在于找到一个能够帮助解决问题的实体,然后委托这个实体解决问题。
在这里,这个具有特定的功能,能够解决特定问题的实体 ,就是一个对象。
由若干个具有相同的特征和行为的对象的组成的集合,就是一个类。
类是对象的集合,对象是类的个体
类的设计与对象的创建 类的设计 从若干个具有相同的特征和行为的对象中,提取出这些相同的特征和行为,设计为一个类
类中定义所有的对象共有的特征和行为,其中,特征用属性表示,行为用方法表示
所谓属性,其实就是定义在类中的一个变量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class 类名{权限修饰符: 成员变量; 成员变量; 成员变量; ...... 权限修饰符: 成员函数1 成员函数2 成员函数3 ...... }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Person {public : string name; string gender; int age; void walk () cout << "人类会走路" << endl; } void eat () cout << "人类会吃饭" << endl; } }
注意事项:
在类中定义的属性、方法,默认都是private的权限,在类外是不能访问的。如果需要在类外访问,需要修改为public权限。
public: 在任意位置都可以访问protected: 在当前类和子类中可以访问private: 只能在当前类中访问
对象的创建 1 2 3 4 5 6 7 8 9 10 int main () Person Tom; Person Tom = Person (); Person* Tom = new Person (); }
在上述的三种创建方式中,前两种方式是类似的。我们在创建对象的时候,区别主要是有没有使用关键字new。
使用new
没有使用new
内存方面
在堆空间开辟
在栈空间开辟
内存管理
需要手动使用delete销毁
不需要手动销毁
属性初始化
自动有默认的初始值
没有初始值
语法
需要用类*来接收变量
不需要使用*
成员访问
通过.访问
通过->访问
成员访问 成员访问,即访问类中的成员(属性、方法)。
1 2 3 4 5 6 7 8 9 10 11 12 int main () Person xiaobai; xiaobai.name = "xiao bai" ; xiaobai.age = 10 ; xiaobai.walk (); xiaobai.eat (); }
1 2 3 4 5 6 7 8 9 10 11 12 int main () Person* xiaobai = new Person (); xiaobai -> name = "xiao bai" ; xiaobai -> age = 1 ; xiaobai -> walk (); xiaobai -> eat (); }
自定义的数据类型(类) 我们在定义类中的属性的时候,可以定义int类型、float类型、字符串类型等等,那么能不能定义为另外的一个类的类型呢?
可以的!类其实就是一种自定义的复杂的数据类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Dog {public : string name; string color; void bark () cout << "汪汪汪" << endl; } }; class Person {public : string name; string gender; int age; Dog dog; void walk () cout << "人类会走路" << endl; } void eat () cout << "人类会吃饭" << endl; } };
类外和其他文件中实现类函数 类外实现 1 2 3 4 5 6 7 8 class Person {public : void walk () } void Person::walk () cout << "person walk" << endl; }
其他文件中实现
如果我们设计的类需要在其他的文件中访问,需要设计头文件!
person.h
1 2 3 4 5 6 7 8 9 #ifndef BASIC_LEARNING_PERSON_H #define BASIC_LEARNING_PERSON_H class Person {public : void walk () }; #endif
person.cpp
1 2 3 4 5 #include "Person.h" void Person::walk () cout << "person walk" << endl; }
静态 我们在类中定义成员的时候(函数、属性),可以使用关键字static来修饰,而这里的关键字static表示的就是静态
在一个类中,被static修饰的成员,称为静态成员,可以分为: 静态属性、静态函数
静态属性
静态的属性内存是开辟在全局区的,与对象无关,并不隶属于对象 。在程序编译的时候,就已经完成了空间的开辟与初始化的赋值操作了,并且在程序运行的整个过程中是始终保持的。
静态属性的空间开辟早于对象的创建 ,并且静态属性不隶属于对象,而是被所有的对象所共享的 。因此,如果你希望某一个属性是可以被所有的对象所共享的,就可以设置为静态的属性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 #include <iostream> using namespace std;namespace part1 { class Person { public : static int countOfObjs; const static int MIN_AGE; }; int Person::countOfObjs = 0 ; const int Person::MIN_AGE = 0 ; } using namespace part1;int main () Person::countOfObjs = 20 ; Person xiaobai; Person xiaohei; xiaohei.countOfObjs = 100 ; cout << xiaobai.countOfObjs << endl; return 0 ; }
静态函数
被关键字static修饰的函数就是静态函数,与静态属性类似,静态函数依然不隶属于某一个对象,而是隶属于当前类的。静态的函数可以使用对象来调用,也可以直接使用类来调用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> using namespace std;namespace part1 { class Person { public : static void test () cout << "person test" << endl; } }; } using namespace part1;int main () Person::test (); return 0 ; }
构造与析构 构造函数的介绍 构造函数,是一个比较特殊的函数。我们在使用一个类的对象的时候,需要为其分配空间。空间分配完成之后,我们一般都会对创建的对象的属性进行初始化的操作。而这个过程就可以在构造函数中来完成了。
因此: 构造函数是一个函数,是在对象创建的时候触发,用来对对象的属性进行初始化的赋值操作。
构造函数的定义
构造函数的名字,必须和类的名字相同!
构造函数不能写返回值类型!
构造函数可以有不同的重载!
1 2 3 4 5 6 7 8 9 10 11 12 class Person {public : Person () { cout << "无参构造函数执行了!" << endl; } Person (int age) { cout << "有参构造函数执行了!参数age = " << age << endl; } }
构造函数的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Person {public : Person () { cout << "Person类的无参构造函数执行了" << endl; } Person (int age) { cout << "Person类的有参构造函数执行了" << endl; } Person (int age, int score) { cout << "Person(int, int)构造函数执行了" << endl; } }; int main () return 0 ; }
explicit关键字 C++提供了关键字explicit,禁止通过构造函数进行的隐式转换。声明为explicit的构造函数不能在隐式转换中使用。
用来修饰构造函数的修饰符,表示无法通过隐式调用来访问这个构造函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Person {public : int age; explicit Person (int a) age = a; } } int main () Person xiaoming = 10 ; return 0 ; }
构造函数注意事项
如果在一个类中,没有手动写任意的构造函数,此时系统会自动为其提供一个public权限的无参构造函数
如果在一个类中,写了任意的一个构造函数,此时系统将不再提供默认的无参构造函数。如果需要的话,需要自己书写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Person {public : int age; Person (int age) { this ->age = age; } } int main () Person p; return 0 ; }
构造函数初始化列表 我们自己书写构造函数,很大的一个用途就是对属性进行初始化的赋值操作,就像如下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Person {public : string name; int age; string gender; int score; Person () { cout << "Person的无参构造函数执行了" << endl; name = "xiaobai" ; age = 18 ; gender = "male" ; score = 99 ; } Person (string n, int a, string g, int s) { cout << "Person的有参构造函数执行了" << endl; name = n; age = a; gender = g; score = s; } }
在上述的代码中,无论是无参的构造函数还是有参的构造函数,我们的目的都是在创建对象的时候,为属性进行初始化的赋值操作。但是重复的这样的赋值有点麻烦,此时,C++为我们提供了初始化列表的方式,来对属性进行初始化的赋值操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Person {public : string name; int age; string gender; int score; Person () : name ("xiaobai" ), age (18 ), gender ("male" ), score (99 ) { cout << "Person的无参构造函数执行了" << endl; } Person (string n, int a, string g, int s) : name (n), age (a), gender (g), score (s) { cout << "Person的有参构造函数执行了" << endl; } }
拷贝构造函数 拷贝构造函数是C++中的另外一种构造函数,这个构造函数也是可以由系统自动提供的。拷贝构造函数,为每一个属性进行赋值。
系统默认的拷贝构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Person {public : string name; int age; Person () { cout << "Person的无参构造函数执行了" << endl; } Person (string n, int a) { name = n; age = a; cout << "Person的有参构造函数执行了" << endl; } } int main () Person p1 ("xiaoming" , 19 ) ; Person p2 (p1) ; cout << "p1.name = " << p1.name << ", p1.age = " << p1.age << endl; cout << "p2.name = " << p2.name << ", p2.age = " << p2.age << endl; return 0 ; }
自己实现拷贝构造函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Person {public : string name; int age; Person () { cout << "Person的无参构造函数执行了" << endl; } Person (string n, int a) { name = n; age = a; cout << "Person的有参构造函数执行了" << endl; } Person (const Person& p) { cout << "Person的拷贝构造函数执行了" << endl; name = p.name; age = p.age; } } int main () Person p1 ("xiaoming" , 19 ) ; Person p2 (p1) ; cout << "p1.name = " << p1.name << ", p1.age = " << p1.age << endl; cout << "p2.name = " << p2.name << ", p2.age = " << p2.age << endl; return 0 ; }
析构函数
我们将一个对象从空间开辟开始,到空间销毁结束,这样的过程称为是一个对象的一生,用生命周期来描述这样的过程。对象的生命周期的起点是构造函数,而对象的生命周期的终点就是析构函数。
析构函数,将会在对象被销毁之前自动调用。
析构函数也是可以由系统自动生成的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Person {public : int age; int * score; Person () { cout << "Person的无参构造函数执行了" << endl; } ~Person () { cout << "Person的析构函数执行了,表示这个对象即将被销毁了" << endl; if (score != NULL ) { delete score; score = NULL ; } } }
深拷贝与浅拷贝的问题 深拷贝与浅拷贝是一个老生常谈的问题,在数组的部分提到过,在面向对象部分也有这两个概念。在这里我们首先需要先区分一下什么是深拷贝,什么是浅拷贝。
浅拷贝: 在拷贝构造函数中,直接完成属性的赋值操作。
深拷贝: 在拷贝构造函数中,创建一个新的空间,使得属性中的指针指向这个新的空间。
浅拷贝案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class Person {public : int age; int * score; Person (int a, int s) { cout << "Person的有参构造函数执行了" << endl; age = a; score = new int (s); } Person (const Person& p) { cout << "拷贝构造函数" << endl; age = p.age; score = p.score; } ~Person () { cout << "析构函数执行了" << endl; if (score != NULL ) { delete score; score = NULL ; } } } int main () Person p1 (18 , 99 ) ; Person p2 (p1) ; cout << p1.score << endl; cout << p2.score << endl; return 0 ; }
深拷贝案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 class Person {public : int age; int * score; Person (int a, int s) { cout << "Person的有参构造函数执行了" << endl; age = a; score = new int (s); } Person (const Person& p) { cout << "拷贝构造函数" << endl; age = p.age; score = new int (*p.score); } ~Person () { cout << "析构函数执行了" << endl; if (score != NULL ) { delete score; score = NULL ; } } } int main () Person p1 (18 , 99 ) ; Person p2 (p1) ; cout << p1.score << endl; cout << p2.score << endl; cout << *p1.score << endl; cout << *p2.score << endl; return 0 ; }
this指针 this是什么 在C++中,this是一个指针,用来指向当前的对象的!
在类中的成员函数的参数列表中默认有一个this参数
1 2 3 4 5 6 7 8 9 10 11 12 class Person {public : Person () {} Person (int a): age (a) {} int getAge () return age; } private : int age; }
在上述代码中,类Person中有一个函数getAge,可以返回属性age的值。那么问题来了,一个类可以有多个对象的。而非静态的属性age是隶属于对象的。不同的对象的age,在内存中的空间肯定也是不同的。如何区分需要返回哪一个对象的age呢?
在一个类中,涉及到成员的访问的时候,非静态的成员访问,通常都会使用this指针来访问。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Person {public : Person () {} Person (int a): age (a) {} int getAge () return this ->age; } private : int age; }
this不可省略的情况 绝大多数的情况下,在一个类的内部,访问当前类中的非静态成员的时候 ,this指针都是可以省略不写的。但是有一种情况,this指针不能省略,必须要显式的写出来:
如果在一个函数中出现了与当前类的属性同名字的局部变量!为了区分局部变量还是属性,此时的this指针不能省略。
1 2 3 4 5 6 7 8 9 10 class Person {public : int age; Person (int age) { this ->age = age; } }
返回当前对象的函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Point {public : int x; int y; Point () {} Point (int x, int y): x (x), y (y) {} Point& add (int deltaX, int deltaY) { x += deltaX; y += deltaY; return *this ; } }
空指针访问成员函数 在C++中,使用空指针是可以访问成员函数的,但是需要注意:不能在函数中出现this指针!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Person {public : int age; Person () {} Person (int age): age (age) {} void testFunction01 () cout << "testFunction01执行了" << endl; } void testFunction02 () if (this == NULL ) { cout << "this是一个空指针" << endl; return ; } cout << "testFunction02执行了" << endl; } void getAge () return age; } } int main () Person* person = NULL ; person->testFunction01 (); person->testFunction02 (); person->getAge (); return 0 ; }
常函数与常对象 什么是常函数
使用关键字const修饰的函数,叫做常函数。
常函数中,不允许修改属性的值。
常函数中,不允许调用其他的普通函数。
如果想要在常函数中修改某个属性的值,需要将这个属性设置为mutable。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Person {public : string name; int age; mutable int score; Person (string name, int age, int score): name (name), age (age), score (score) {} void fixPerson (string newName, int newAge, int newScore) const name = newName; age = newAge; score = newScore; test (); } void test () }
常对象
在对象创建的时候,使用const修饰的对象,就是常对象
常对象可以访问任意的属性值,但是不能修改普通属性的值
常对象可以修改mutable属性的值
常对象只能调用常函数
1 2 3 4 5 6 7 8 9 int main () const Person person ("zhangsan" , 18 , 99 ) cout << person.name << endl; person.age = 100 ; person.score = 200 ; }
友元 友元是什么 类的主要特点之一是数据隐藏,即类的私有成员无法在类的外部(作用域之外)访问。但是,有时候需要在类的外部访问类的私有成员,怎么办?
解决方法是使用友元函数,友元函数是一种特权函数,C++允许这个特权函数访问私有成员
程序员可以把一个全局函数、某个类中的成员函数、甚至整个类声明为友元。
全局函数做友元 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Home { friend void gotoBed (Home* home) public : string livingRoom = "这里是客厅" ; private : string bedRoom = "这里是卧室" ; }; void gotoBed (Home* home) cout << home->livingRoom << endl; cout << home->bedRoom << endl; } int main () Home home; gotoBed (&home); return 0 ; }
成员函数做友元 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Home ;class GoodGay {public : GoodGay (); void visit () private : Home* home; }; class Home { friend void GoodGay::visit () public : string livingRoom = "客厅" ; private : string bedRoom = "卧室" ; }; GoodGay::GoodGay () { this ->home = new Home (); } void GoodGay::visit () cout << home->livingRoom << endl; cout << home->bedRoom << endl; } int main () GoodGay gay; gay.visit (); return 0 ; }
类做友元 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Home ;class GoodGay {public : GoodGay (); void visit () private : Home* home; }; class Home { friend class GoodGay ; public : string livingRoom = "客厅" ; private : string bedRoom = "卧室" ; }; GoodGay::GoodGay () { home = new Home (); } void GoodGay::visit () cout << home->livingRoom << endl; cout << home->bedRoom << endl; } int main () GoodGay gay; gay.visit (); return 0 ; }
运算符重载 什么是运算符重载
运算符重载,就是对已有的运算符重新进行定义 ,赋予其另一种功能,以适应不同的数据类型。
运算符重载(operator overloading)只是一种语法上的方便 ,也就是它只是另一种函数调用的方式。处理类的新运算符。这种定义很像一个普通的函数定义,只是函数的名字由关键字operator及其紧跟的运算符组成。差别仅此而已。它像任何其他函数一样也是一个函数,当编译器遇到适当的模式时,就会调用这个函数。
语法: operator@,这里的@代表了被重载的运算符。函数的参数中参数个数取决于两个因素。
运算符是一元(一个参数)的还是二元(两个参数);
运算符被定义为全局函数(对于一元是一个参数,对于二元是两个参数)还是成员函数(对于一元没有参数,对于二元是一个参数-此时该类的对象用作左耳参数)
注意:
可重载的运算符 几乎所有的运算符都可以重载,但运算符重载的使用时相当受限制的。特别是不能改变运算符优先级,不能改变运算符的参数个数。这样的限制有意义,否则,所有这些行为产生的运算符只会混淆而不是澄清语意。
可重载的运算符
+
-
*
/
%
^
&
|
~
!
=
<
>
+=
-=
*=
/=
%=
^=
&=
|=
<<
>>
>>=
<<=
==
!=
<=
>=
&&
||
++
–
->*
‘
->
[]
()
new
delete
new[]
delete[]
不可重载的运算符
运算符重载: + 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Point {public : int x; int y; Point (): x (0 ), y (0 ) {} Point (int x, int y): x (x), y (y) {} Point operator +(const Point& p) const { return {x + p.x, y + p.y}; } }; Point operator -(const Point& p1, const Point& p2) { return {p1.x - p2.x, p1.y - p2.y}; } int main () Point p1 (10 , 20 ) ; Point p2 (15 , 25 ) ; Point res = p1 + p2; cout << "res.x = " << res.x << ", res.y = " << res.y << endl; Point res2 = p1 - p2; cout << "res2.x = " << res2.x << ", res2.y = " << res2.y << endl; return 0 ; }
运算符重载: ++ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class Point {public : int x; int y; Point (): x (0 ), y (0 ) {} Point (int x, int y): x (x), y (y) {} Point operator ++() { x++; y++; return *this ; } Point operator ++(int ) { Point tmp = *this ; x++; y++; return tmp; } }; Point operator --(Point& point) { point.x--; point.y--; return point; } Point operator --(Point& point, int ) { Point tmp = point; point.x--; point.y--; return tmp; } int main () Point p1 (10 , 20 ) ; Point p2 (15 , 25 ) ; Point res1 = ++p1; cout << "res1.x = " << res1.x << ", res1.y = " << res1.y << endl; cout << "p1.x = " << p1.x << ", p1.y = " << p1.y << endl; Point res2 = p2++; cout << "res2.x = " << res2.x << ", res2.y = " << res2.y << endl; cout << "p2.x = " << p2.x << ", p2.y = " << p2.y << endl; return 0 ; }
运算符重载: << 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Point { friend ostream& operator <<(ostream& os, const Point& p); public : int x; int y; Point (): x (0 ), y (0 ), privateField (0 ) {} Point (int x, int y): x (x), y (y), privateField (0 ) {} private : int privateField; }; ostream& operator <<(ostream& os, const Point& p) { os << "x = " << p.x << ", y = " << p.y << ", privateField = " << p.privateField; return os; } int main () Point p1 (10 , 20 ) ; cout << "p1: " << p1 << endl; return 0 ; }
运算符重载: = 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class Person {public : int age; int score; int * p; Person (): age (0 ), score (0 ), p (nullptr ) {} Person (const Person& person) { cout << "拷贝构造函数执行了" << endl; age = person.age; score = person.score; p = new int (*person.p); } Person& operator =(const Person& person) { cout << "重载赋值运算符执行了" << endl; age = person.age; score = person.score; p = new int (*person.p); return *this ; } ~Person () { cout << "析构函数执行了" << endl; if (p == nullptr ) { delete p; p = nullptr ; } } }; int main () Person p1; p1.age = 18 ; p1.score = 99 ; p1.p = new int (100 ); Person p2 = p1; p2.age = 20 ; p2.score = 100 ; p2.p = new int (200 ); p1 = p2; cout << p1.age << ", " << p1.score << ", " << p1.p << " =>" << *p1.p << endl; cout << p2.age << ", " << p2.score << ", " << p2.p << " =>" << *p2.p << endl; return 0 ; }
封装
面向对象编程思想中,有三大特性:封装、继承、多态。
封装可以有广义和狭义上的概念。广义上的封装,我们可以将一些功能相近的一些类放入一个模块中。这里我们更多强调的是狭义上的封装性。
定义:我们可以通过对具体属性的封装实现.把对成员变量的访问进行私有化,让他只能在类内部可见,通过公共的方法间接实现访问
优点:提高了代码的安全性,复用性和可读性.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Student { private : string name; int age; public : Student (): name ("" ), age (0 ) {} Student (string name, int age) {} void setName (string name) this ->name = name; } void getName () return name; } void setAge (int age) if (age >= 0 && age <= 130 ) { this ->age = age; } } int getAge () return age; } }
继承 程序中的继承 在现实生活中,我们与父母有继承的关系,在java中也存在继承的思想,来提高代码的复用性、代码的拓展性。
程序中的继承,是类与类之间的特征和行为的一种赠予或获取。一个类可以将自己的属性和方法赠予其他的类,一个类也可以从其他的类中获取他们的属性和方法。
两个类之间的继承,必须满足 is a 的关系。
两个类之间,A类将属性和特征赠予B类。此时A类被称为是父类 ,B类被称为是子类 ,两者之间的关系是子类继承自父类
继承的语法 在C++中,在定义类的时候,类名后面使用冒号来定义父类。
类中的所有成员都可以继承给子类,但是私有的成员,由于访问权限的限制,子类无法访问。
一个类在继承了其他类之后,也可以被其他类继承。
使用继承,可以简化代码、提高代码的复用性、提高代码的拓展性,最重要的是让类与类之间产生了继承关系,是多态的前提。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Animal {public : int age; } class Dog : public Animal { void test () cout << age << endl; } } int main () Dog dog; dog.test (); return 0 ; }
继承的三种方式 在C++中,继承有三种方式,分别是:公共继承、保护继承和私有继承。其实只是一个访问权限的问题。
公共继承: 继承到父类中的属性,保留原本的访问权限(私有除外)保护继承: 继承到父类中的属性,超过protected权限的部分将降为protected权限(私有除外)私有继承: 继承到父类中的属性,访问权限都为private权限(私有除外)
C++中默认使用的是私有继承!
公共继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class BaseClass {public : int publicField; protected : int protectedField; private : int privateField; } class SubClass : public BaseClass { void test () cout << publicField << endl; cout << protectedField << endl; } } int main () SubClass sc; cout << sc.publicField << endl; }
保护继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class BaseClass {public : int publicField; protected : int protectedField; private : int privateField; } class SubClass : protected BaseClass { void test () cout << publicField << endl; cout << protectedField << endl; } } int main () SubClass sc; }
私有继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class BaseClass {public : int publicField; protected : int protectedField; private : int privateField; } class SubClass : public BaseClass { void test () cout << publicField << endl; cout << protectedField << endl; } } int main () SubClass sc; }
继承中的构造和析构 子类对象在创建的时候,需要先调用父类中的构造函数,用来初始化父类部分。因此,子类对象创建的时候,先调用父类的构造函数,再调用子类自己的构造函数。
而析构函数的调用正好相反,先调用子类的析构函数,再调用父类的析构函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class Animal {public : int age; Animal () { age = 0 ; cout << "父类中的无参构造函数调用了" << endl; } explicit Animal (int age) : age(age) { cout << "父类中的有参构造函数调用了" << endl; } ~Animal () { cout << "父类中的析构函数调用了" << endl; } }; class Dog : public Animal {public : explicit Dog () cout << "子类中的无参构造函数被调用了" << endl; } ~Dog () { cout << "子类中的析构函数被调用了" << endl; } }; int main () Dog dog () ; return 0 ; }
从上述的代码中可以看到,子类对象在创建的时候,需要先调用父类中的构造函数来构造父类部分。这里默认是调用父类中的无参构造函数。那么问题来了:如果父类中没有无参构造函数,或者父类中的无参构造函数是私有的,怎么办?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Animal {public : int age; explicit Animal (int age) : age(age) { cout << "父类中的有参构造函数调用了" << endl; } ~Animal () { cout << "父类中的析构函数调用了" << endl; } }; class Dog : public Animal {public : explicit Dog (int age) : Animal(age) { cout << "子类中的无参构造函数被调用了" << endl; } ~Dog () { cout << "子类中的析构函数被调用了" << endl; } }; int main () Dog dog (0 ) ; return 0 ; }
父类子类成员同名的情况 如果父类和子类中出现了同名字的成员(属性、函数),子类会将从父类继承到的成员隐藏起来。此时使用子类对象来访问的时候,默认访问的是子类中的成员。如果想要访问父类中的成员,需要手动指定作用域。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Animal {public : int age = 10 ; void showAge () const cout << "父类中的函数showAge被调用,age = " << age << endl; } }; class Dog : public Animal {public : int age; void showAge () const cout << "子类中的函数showAge被调用,age = " << age << endl; } }; int main () Dog dog; dog.age = 2 ; dog.showAge (); dog.Animal::showAge (); cout << dog.age << endl; cout << dog.Animal::age << endl; return 0 ; }
多继承 多继承语法 我们可以从一个类继承,我们也可以能同时从多个类继承,这就是多继承。但是由于多继承是非常受争议的,从多个类继承可能会导致函数、变量等同名导致较多的歧义。
多继承会带来一些二义性的问题,如果两个基类中有同名的函数或者变量,那么通过派生类对象去访问这个函数或变量时就不能明确到底调用从基类1继承的版本还是从基类2继承的版本?
解决方法就是显示指定调用那个基类的版本。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Base1 {public : void func1 () "Base1::func1" << endl; } }; class Base2 {public : void func1 () "Base2::func1" << endl; } void func2 () "Base2::func2" << endl; } }; class Derived : public Base1, public Base2{};int main () Derived derived; derived.func2 (); derived.Base1::func1 (); derived.Base2::func1 (); return 0 ; }
菱形继承 两个派生类继承同一个基类而又有某个类同时继承者两个派生类,这种继承被称为菱形继承,或者钻石型继承。
这种继承所带来的问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class BigBase {public : BigBase (){ mParam = 0 ; } void func () "BigBase::func" << endl; } public : int mParam; }; class Base1 : public BigBase {}; class Base2 : public BigBase {}; class Derived : public Base1, public Base2 { }; int main () Derived derived; cout << "derived.Base1::mParam:" << derived.Base1::mParam << endl; cout << "derived.Base2::mParam:" << derived.Base2::mParam << endl; return 0 ; }
虚继承 Base1,Base2采用虚继承方式继承BigBase,那么BigBase被称为虚基类。
通过虚继承解决了菱形继承所带来的二义性问题。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class BigBase {public : BigBase (){ mParam = 0 ; } void func () "BigBase::func" << endl; } public : int mParam; }; class Base1 : virtual public BigBase{};class Base2 : virtual public BigBase{};class Derived : public Base1, public Base2{};int main () Derived derived; derived.func (); cout << derived.mParam << endl; cout << "Derived size:" << sizeof (Derived) << endl; return EXIT_SUCCESS; }
多态 多态的基本概念 什么是多态 生活中的多态,是指的客观的事物在人脑中的主观体现。例如,在路上看到一只哈士奇,你可以看做是哈士奇,可以看做是狗,也可以看做是动物。主观意识上的类别,与客观存在的事物,存在 is a 的关系的时候,即形成了多态。
在程序中,一个类的引用指向另外一个类的对象,从而产生多种形态。当二者存在直接或者间接的继承关系时,父类引用指向子类的对象,即形成多态。
多态是面向对象三大特性之一,记住继承是多态的前提,如果类与类之间没有继承关系,也不会存在多态。
多态的分类 c++支持编译时多态(静态多态)和运行时多态(动态多态),运算符重载和函数重载就是编译时多态,而派生类和虚函数实现运行时多态。
静态多态和动态多态的区别就是函数地址是早绑定(静态联编)还是晚绑定(动态联编)。如果函数的调用,在编译阶段就可以确定函数的调用地址,并产生代码,就是静态多态(编译时多态),就是说地址是早绑定的。而如果函数的调用地址不能编译不能在编译期间确定,而需要在运行时才能决定,这这就属于晚绑定(动态多态,运行时多态)。
对象转型 对象可以作为自己的类或者作为它的基类的对象来使用。还能通过基类的地址来操作它。取一个对象的地址(指针或引用),并将其作为基类的地址来处理,这种称为向上类型转换。
也就是说:父类引用或指针可以指向子类对象,通过父类指针或引用来操作子类对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 class Animal {public : void bark () cout << "Animal Bark" << endl; } }; class Dog : public Animal {public : void bark () cout << "Dog Bark" << endl; } }; int main () Dog dog; Animal& animal = dog; animal.bark (); return 0 ; }
虚函数
上述代码的运行结果是: Animal bark。说明执行的是父类中的bark函数,而非子类中的函数。
于是现在就有一个问题出现了: 为什么?animal的引用指向的实际上是一个Dog对象,但是为什么会调用父类中的函数实现呢?
解决这个问题,我们需要了解下绑定(捆绑,binding)概念。
把函数体与函数调用相联系称为绑定(捆绑,binding)
当绑定在程序运行之前(由编译器和连接器)完成时,称为早绑定(early binding)。
上面的问题就是由于早绑定引起的,因为编译器在只有Animal地址时并不知道要调用的正确函数。编译是根据指向对象的指针或引用的类型来选择函数调用。这个时候由于调用函数的时候使用的是Animal类型,编译器确定了应该调用的bark是Animal::bark的,而不是真正传入的对象Dog::bark。
解决方法就是迟绑定(迟捆绑,动态绑定,运行时绑定,late binding),意味着绑定要根据对象的实际类型,发生在运行。
C++语言要实现这种动态绑定,必须有某种机制来确定运行时对象的类型并调用合适的成员函数。对于一种编译语言,编译器并不知道实际的对象类型(编译器并不知道Animal类型的指针或引用指向的实际的对象类型)
C++动态多态性是通过虚函数来实现的,虚函数允许子类(派生类)重新定义父类(基类)成员函数,而子类(派生类)重新定义父类(基类)虚函数的做法称为覆盖(override),或者称为重写。对于特定的函数进行动态绑定,C++要求在基类中声明这个函数的时候使用virtual关键字,动态绑定也就对virtual函数起作用。
为创建一个需要动态绑定的虚成员函数,可以简单在这个函数声明前面加上virtual关键字,定义时候不需要.
如果一个函数在基类中被声明为virtual,那么在所有派生类中它都是virtual的.
在派生类中virtual函数的重定义称为重写(override).
virtual关键字只能修饰成员函数.
构造函数不能为虚函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Animal {public : virtual void bark () cout << "Animal Bark" << endl; } }; class Dog : public Animal {public : void bark () override cout << "Dog Bark" << endl; } }; int main () Dog dog; Animal& animal = dog; animal.bark (); return 0 ; }
多态案例 未使用多态实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class SF { void sendPackage () cout << "SF快递为你快速发送包裹" << endl; } }; class EMS { void sendPackage () cout << "EMS快递为您发送包裹,哪里都能送到!" << endl; } }; class JDL { void sendPackage () cout << "JDL快递为您发送包裹,最快当日可达!" << endl; } }; void sendPackage (string company) if (company == "SF" ) { new SF ().sendPackage (); } else if (company == "EMS" ) { new EMS ().sendPackage (); } else if (company == "JDL" ) { new JDL ().sendPackage (); } }
使用多态实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class ExpressCompany {public : virtual void sendPackage () cout << "快递公司发送包裹" << endl; } }; class SF : public ExpressCompany { void sendPackage () override cout << "SF快递为你快速发送包裹" << endl; } }; class EMS : public ExpressCompany { void sendPackage () override cout << "EMS快递为您发送包裹,哪里都能送到!" << endl; } }; class JDL : public ExpressCompany { void sendPackage () override cout << "JDL快递为您发送包裹,最快当日可达!" << endl; } }; void sendPackage (ExpressCompany& express) express.sendPackage (); } int main () sendPackage (*(new SF)); sendPackage (*(new EMS)); sendPackage (*(new JDL)); return 0 ; }
纯虚函数与抽象类 在设计程序时,常常希望基类仅仅作为其派生类的一个接口。这就是说,仅想对基类进行向上类型转换,使用它的接口,而不希望用户实际的创建一个基类的对象。同时创建一个纯虚函数允许接口中放置成员原函数,而不一定要提供一段可能对这个函数毫无意义的代码。
1 2 例如: 我们可以设计一个交通工具类,提供最基础的运输的功能。我们在使用到交通工具的时候,往往并不是寻求交通工具的对象,而是寻求的交通工具子类的对象,例如公交车、例如地铁、例如共享单车等。而我们需要的其实是在这些子类中的运输功能实现。因此,父类交通工具类中的运输功能怎么去实现没有意义。
纯虚函数使用virtual来修饰一个函数,并且实现部分直接设置为0。
1 virtual void test() = 0;
如果一个类中包含了纯虚函数,那么这个类也自动的编程了抽象类了。抽象类无法实例化对象,并且子类必须重写实现父类中的纯虚函数,否则子类也是抽象类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class TrafficTools {public : virtual void transport () 0 ; }; class Bus : public TrafficTools {public : void transport () override cout << "公交车运输乘客" << endl; } }; class Subway : public TrafficTools {public : void transport () override cout << "地铁运输乘客" << endl; } }; void useTrafficTools (TrafficTools& trafficTools) trafficTools.transport (); } int main () useTrafficTools (*(new Bus)); useTrafficTools (*(new Subway)); return 0 ; }
纯虚函数与多继承 多继承带来了一些争议,但是接口继承可以说一种毫无争议的运用了。
接口类中只有函数原型定义,没有任何数据定义。
多重继承接口不会带来二义性和复杂性问题。接口类只是一个功能声明,并不是功能实现,子类需要根据功能说明定义功能实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Cooker {public : virtual void buyFood () 0 ; virtual void cook () 0 ; virtual void eat () 0 ; }; class Maid {public : virtual void cook () 0 ; virtual void clean () 0 ; virtual void wash () 0 ; }; class Person : public Cooker, public Maid {public : void buyFood () override "买菜" << endl; } void cook () override "做饭" << endl; } void eat () override "吃饭" << endl; } void clean () override "扫地" << endl; } void wash () override "洗衣服" << endl; } }; int main () Person xiaoming; xiaoming.buyFood (); xiaoming.cook (); xiaoming.eat (); xiaoming.wash (); xiaoming.clean (); return 0 ; }
虚析构函数 析构函数是对象生命周期的终点,在对象被销毁之前调用。在析构函数中,我们一般会进行资源的释放、空间的销毁的操作。例如,在一个类中有指向堆空间内存的指针,我们需要通过这样的指针来销毁对应的堆空间。但是,在多态中,父类的引用可以指向子类的对象,那么我们在使用父类的引用来销毁空间的话,就有可能会出现子类中引用的堆空间无法销毁的情况,造成内存泄漏。而解决方案就是为父类添加虚析构函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Animal {public : virtual ~Animal () { cout << "父类的析构函数执行了" << endl; } }; class Person : public Animal {public : int * n; Person () { n = new int (10 ); } ~Person () override { cout << "子类的析构函数执行了" << endl; if (n != nullptr ) { delete n; n = nullptr ; } } }; int main () Animal* animal = new Person (); delete animal; return 0 ; }
虚析构函数也可以做成纯虚析构函数,如果一个类中包含了纯虚析构函数,那么这个类依然是一个抽象类,无法实例化对象。
总结:
如果一个类的目的不是为了实现多态,仅仅是作为一个基类来使用,那么无需将析构函数设置为虚析构函数。
如果一个类的目的就是为了实现多态的,那么这个类的析构函数就有必要设置为虚析构函数。
结构体 结构体的定义与使用 在C++中,还有一种用户自定义的数据类型,结构体。结构体的定义与使用基本与类相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 struct Student { string name; int age; Student () { name = "" ; age = 0 ; } Student (string name, int age): name (name), age (age) {} void study () const cout << name << "正在努力学习" << endl; } ~Student () { cout << "结构体析构函数" << endl; } }; int main () struct Student student; student.name = "zhangsan" ; student.age = 18 ; student.study (); struct Student xiaoming ("xiaoming" , 12 ); struct Student xiaohei = Student ("xiaohei" , 11 ); struct Student xiaobai = {"xiaobai" , 10 }; struct Student * xiaoli = new Student ("xiaoli" , 11 ); delete xiaoli; return 0 ; }
结构体与类的区别 C++对结构体进行了很多的拓展,是的C++对结构体用于与类几乎相同的功能:可以设计属性、函数,可以设计构造、析构,甚至可以有继承,可以有多态。现在看来C++的结构体与类的区别,主要是一点:默认的访问权限不同
类成员默认的访问权限是private
结构体成员默认的访问权限是public
模板 模板的介绍 c++提供了函数模板(function template)。所谓函数模板,实际上是建立一个通用函数,其函数类型和形参类型不具体制定,用一个虚拟的类型来代表。这个通用函数就称为函数模板。凡是函数体相同的函数都可以用这个模板代替,不必定义多个函数,只需在模板中定义一次即可。在调用函数时系统会根据实参的类型来取代模板中的虚拟类型,从而实现不同函数的功能。
c++提供两种模板机制:函数模板 和类模板
总结:
函数模板 函数模板的定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 void mySwap (int & a, int & b) int tmp = a; a = b; b = tmp; } void mySwap (double & a, double & b) double tmp = a; a = b; b = tmp; }
1 2 3 4 5 6 7 8 9 10 template <typename T>void mySwap (T& a, T& b) T tmp = a; a = b; b = tmp; }
函数模板的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 template <class T>void mySwap (T& a, T& b) T tmp = a; a = b; b = tmp; } int main () int a = 10 , b = 20 ; double x = 3.14 , y = 0.99 ; mySwap <int >(a, b); mySwap (a, b); mySwap (x, y); return 0 ; }
函数模板案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 template <class T>void mySort (T array[], int len) for (int i = 0 ; i < len - 1 ; i++) { int minIndex = i; for (int j = i + 1 ; j < len; j++) { if (array[minIndex] > array[j]) { minIndex = j; } } if (minIndex != i) { T tmp = array[minIndex]; array[minIndex] = array[i]; array[i] = tmp; } } } template <class T>void showArray (T array[], int len) if (len == 0 ) { cout << "[]" << endl; return ; } cout << "[" ; for (int i = 0 ; i < len - 1 ; i++) { cout << array[i] << ", " ; } cout << array[len - 1 ] << "]" << endl; } int main () int array1[] = {1 , 3 , 5 , 7 , 9 , 0 , 8 , 6 , 4 , 2 }; int len1 = sizeof (array1) / sizeof (int ); mySort (array1, len1); showArray (array1, len1); double array2[] = {3.14 , 9.28 , 3 , 3.44 , -9.2 , 8.22 }; int len2 = sizeof (array2) / sizeof (double ); mySort (array2, len2); showArray (array2, len2); char array3[] = {'a' , 'l' , '1' , 'm' , 'k' }; int len3 = sizeof (array3) / sizeof (char ); mySort (array3, len3); showArray (array3, len3); return 0 ; }
函数模板与普通函数 函数模板和普通函数在调用的时候,需要注意:
普通函数调用,是可以发生自动的类型转换的;函数模板调用,是不可以发生自动的类型转换的
如果调用函数的时候,实参既可以匹配普通函数,又可以匹配函数模板,则优先匹配普通函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 template <class T>int myPlus (const T& n1, const T& n2) return n1 + n2; } int myPlus (int n1, int n2) return n1 + n2; } int main () int n1 = 10 ; char c = 'a' ; myPlus (n1, c); myPlus (10 , 20 ); return 0 ; }
函数模板的局限性 函数模板虽然很通用,但是并不是万能的,有时候也会有不适配的情况出现。
1 2 3 4 template <class T>bool compare (const T& t1, const T& t2) return t1 > t2; }
对于上述的函数模板来说,如果是比较整型、浮点型甚至字符类型的数据都是没有问题的。可是如果我设置为Person类型呢?两个Person对象无法使用>进行比较,这里自然也就出问题了。
那么如何解决这样的问题呢?
重载运算符,重载>运算符。
通过函数模板的重载来解决。
函数模板的重载,就是为了解决特定类型的对象的问题,通过函数模板的重载,可以为这些特定的数据类型提供具像化的模板。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Person {public : int age; }; template <class T>bool compare (const T& t1, const T& t2) return t1 > t2; } template <>bool compare <Person>(const Person& p1, const Person& p2) { return p1.age > p2.age; } int main () Person p1; p1.age = 15 ; Person p2; p2.age = 12 ; cout << compare (p1, p2) << endl; return 0 ; }
类模板 类模板的定义 类模板和函数模板的定义和使用基本是一样的,如何定义函数模板,就如何定义类模板。但是类模板与函数模板还是有点区别的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 template <class T1 , class T2 = int >class NumberOperator {public : T1 num1; T2 num2; void cal () cout << num1 + num2 << endl; } }; int main () NumberOperator<int , int > op1; op1.num1 = 10 ; op1.num2 = 20 ; op1.cal (); NumberOperator<double > op2; op2.num1 = 3.14 ; op2.num2 = 10 ; op2.cal (); return 0 ; }
类模板做函数参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 template <class T1 , class T2 = int >class NumberOperation {public : T1 num1; T2 num2; void cal () cout << num1 + num2 << endl; } }; void useNumberOperation (NumberOperation<int , int >& op) op.cal (); } template <typename T1, typename T2>void useNumberOperation02 (NumberOperation<T1, T2>& op) op.cal (); } int main () NumberOperation<int , int > op; op.num1 = 10 ; op.num2 = 20 ; useNumberOperation (op); useNumberOperation02 (op); NumberOperation<double , int > op2; op2.num1 = 10.5 ; op2.num2 = 5 ; useNumberOperation02 (op2); return 0 ; }
类模板继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 template <typename T>class Animal {public : T arg; }; class Dog : Animal<int > { }; template <typename E>class Person : Animal<E> { };
类模板中的成员函数创建时机 类模板中的成员函数在编译的时候是不会创建的,是在调用这个函数的时候创建。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class Dog {public : void bark () "汪汪" << endl; } } class Cat {public : void sleep () "呼呼" << endl; } } template <typename T>class Person {public : T pet; void makeBark () pet.bark (); } void makeSleep () pet.sleep (); } } int main () Person<Dog> xiaobai; xiaobai.makeBark (); xiaobai.makeSleep (); return 0 ; }
类模板类外实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 template <typename T, typename M>class NumberCalculator {private : T n1; M n2; public : NumberCalculator () {} NumberCalculator (T n1, M n2); void add () }; template <typename T, typename M>NumberCalculator<T, M>::NumberCalculator (T n1, M n2) { this ->n1 = n1; this ->n2 = n2; } template <typename T, typename M>NumberCalculator<T, M>::add () { cout << n1 + n2 << endl; }
类模板头文件和原文件分离问题 我们在写程序的时候,很多时候都是需要将类的声明和实现分开来写。将类的声明部分写到.h文件中,将类的实现部分写在.cpp文件中。在使用到这个类的时候,直接包含.h文件即可。但是,如果是一个模板类,这样做是有问题的。
NumberCalculator.h
1 2 3 4 5 6 7 8 9 10 11 12 13 #pragma once template <typename T, typename M>class NumberCalculator {private : T n1; M n2; public : NumberCalculator () {} NumberCalculator (T n1, M n2); void add () };
NumberCalculator.cpp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #include <iostream> #include "NumberCalculator.h" using namespace std;template <typename T, typename M>NumberCalculator<T, M>::NumberCalculator (T n1, M n2) { this ->n1 = n1; this ->n2 = n2; } template <typename T, typename M>void NumberCalculator<T, M>::add () { cout << n1 + n2 << endl; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int main () NumberCalculator<int , int > cal1; NumberCalculator<int , int > cal2 (10 , 20 ) ; }
类模板遇到友元 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 template <typename T, typename M>class NumberCalculator ;template <typename T, typename M>void printNumberCalculator (const NumberCalculator<T, M>& op) cout << "n1 = " << op.n1 << ", n2 = " << op.n2 << endl; } template <typename T, typename M>class NumberCalculator { friend void printNumberCalculator<>(const NumberCalculator<T, M>& op); private : T n1; M n2; public : NumberCalculator (); NumberCalculator (T n1, M n2); }; template <typename T, typename M>NumberCalculator<T, M>::NumberCalculator (T n1, M n2) { this ->n1 = n1; this ->n2 = n2; } template <typename T, typename M>NumberCalculator<T, M>::NumberCalculator () = default ; int main () NumberCalculator<int , int > op (10 , 20 ) ; printNumberCalculator (op); return 0 ; }
STL标准模板库 STL概述 长久以来,软件界一直希望建立一种可重复利用的东西,以及一种得以制造出”可重复运用的东西”的方法,让程序员的心血不止于随时间的迁移,人事异动而烟消云散,从函数(functions),类别(classes),函数库(function libraries),类别库(class libraries)、各种组件,从模块化设计,到面向对象(object oriented ),为的就是复用性的提升。
复用性必须建立在某种标准之上。但是在许多环境下,就连软件开发最基本的数据结构(data structures) 和算法(algorithm)都未能有一套标准。大量程序员被迫从事大量重复的工作,竟然是为了完成前人已经完成而自己手上并未拥有的程序代码,这不仅是人力资源的浪费,也是挫折与痛苦的来源。
为了建立数据结构和算法的一套标准,并且降低他们之间的耦合关系,以提升各自的独立性、弹性、交互操作性(相互合作性,interoperability),诞生了STL。
STL基本概念 STL(Standard Template Library,标准模板库),是惠普实验室开发的一系列软件的统称。现在主要出现在 c++中,但是在引入 c++之前该技术已经存在很长时间了。
STL 从广义上分为: 容器(container) 算法(algorithm) 迭代器(iterator),容器和算法之间通过迭代器进行无缝连接。STL 几乎所有的代码都采用了模板类或者模板函数,这相比传统的由函数和类组成的库来说提供了更好的代码重用机会。STL(Standard Template Library)标准模板库,在我们 c++标准程序库中隶属于 STL 的占到了 80%以上。
STL六大组件简介 STL提供了六大组件,彼此之间可以组合套用,这六大组件分别是:容器、算法、迭代器、仿函数、适配器(配接器)、空间配置器。
容器: 各种数据结构,如vector、list、deque、set、map等,用来存放数据,从实现角度来看,STL容器是一种class template。
算法: 各种常用的算法,如sort、find、copy、for_each。从实现的角度来看,STL算法是一种function tempalte.
迭代器: 扮演了容器与算法之间的胶合剂,共有五种类型,从实现角度来看,迭代器是一种将operator* , operator-> , operator++,operator–等指针相关操作予以重载的class template. 所有STL容器都附带有自己专属的迭代器,只有容器的设计者才知道如何遍历自己的元素。原生指针(native pointer)也是一种迭代器。
仿函数: 行为类似函数,可作为算法的某种策略。从实现角度来看,仿函数是一种重载了operator()的class 或者class template
适配器: 一种用来修饰容器或者仿函数或迭代器接口的东西。
空间配置器: 负责空间的配置与管理。从实现角度看,配置器是一个实现了动态空间配置、空间管理、空间释放的class tempalte.
STL六大组件的交互关系,容器通过空间配置器取得数据存储空间,算法通过迭代器存储容器中的内容,仿函数可以协助算法完成不同的策略的变化,适配器可以修饰仿函数。
STL优点 STL 是 C++的一部分,因此不用额外安装什么,它被内建在你的编译器之内。
STL 的一个重要特性是将数据和操作分离。数据由容器类别加以管理,操作则由可定制的算法定义。迭代器在两者之间充当“粘合剂”,以使算法可以和容器交互运作。程序员可以不用思考 STL 具体的实现过程,只要能够熟练使用 STL 就 OK 了。这样他们就可以把精力放在程序开发的别的方面。
STL 具有高可重用性,高性能,高移植性,跨平台的优点。
高可重用性:STL 中几乎所有的代码都采用了模板类和模版函数的方式实现,这相比于传统的由函数和类组成的库来说提供了更好的代码重用机会。关于模板的知识,已经给大家介绍了。
高性能:如 map 可以高效地从十万条记录里面查找出指定的记录,因为 map 是采用红黑树的变体实现的。
高移植性:如在项目 A 上用 STL 编写的模块,可以直接移植到项目 B 上。
STL三大组件 容器 容器,置物之所也。
研究数据的特定排列方式,以利于搜索或排序或其他特殊目的,这一门学科我们称为数据结构。大学信息类相关专业里面,与编程最有直接关系的学科,首推数据结构与算法。几乎可以说,任何特定的数据结构都是为了实现某种特定的算法。STL容器就是将运用最广泛的一些数据结构实现出来。
常用的数据结构:数组(array),链表(list),tree(树),栈(stack),队列(queue),集合(set),映射表(map),根据数据在容器中的排列特性,这些数据分为序列式容器和关联式容器两种。
序列式容器强调值的排序,序列式容器中的每个元素均有固定的位置,除非用删除或插入的操作改变这个位置。Vector容器、Deque容器、List容器等。
关联式容器是非线性的树结构,更准确的说是二叉树结构。各元素之间没有严格的物理上的顺序关系,也就是说元素在容器中并没有保存元素置入容器时的逻辑顺序。关联式容器另一个显著特点是:在值中选择一个值作为关键字key,这个关键字对值起到索引的作用,方便查找。Set/multiset容器 Map/multimap容器
容器可以嵌套容器!
算法 算法,问题之解法也。
以有限的步骤,解决逻辑或数学上的问题,这一门学科我们叫做算法(Algorithms).
广义而言,我们所编写的每个程序都是一个算法,其中的每个函数也都是一个算法,毕竟它们都是用来解决或大或小的逻辑问题或数学问题。STL收录的算法经过了数学上的效能分析与证明,是极具复用价值的,包括常用的排序,查找等等。特定的算法往往搭配特定的数据结构,算法与数据结构相辅相成。
算法分为: 质变算法 非质变算法
迭代器 迭代器(iterator)是一种抽象的设计概念,现实程序语言中并没有直接对应于这个概念的实物。iterator定义如下:提供一种方法,使之能够依序寻访某个容器所含的各个元素,而又无需暴露该容器的内部表示方式。
迭代器的设计思维-STL的关键所在,STL的中心思想在于将容器(container)和算法(algorithms)分开,彼此独立设计,最后再一贴胶着剂将他们撮合在一起。从技术角度来看,容器和算法的泛型化并不困难,c++的class template和function template可分别达到目标,如何设计出两这个之间的良好的胶着剂,才是大难题。
迭代器的种类:
输入迭代器
提供对数据的只读访问
只读,支持++、==、!=
输出迭代器
提供对数据的只写访问
只写,支持++
前向迭代器
提供读写操作,并能向前推进迭代器
读写,支持++、==、!=
双向迭代器
提供读写操作,并能向前和向后操作
读写,支持++、–,
随机访问迭代器
提供读写操作,并能以跳跃的方式访问容器的任意数据,是功能最强的迭代器
读写,支持++、–、[n]、-n、<、<=、>、>=
常用容器 string容器 string容器基本概念 C风格字符串(以空字符结尾的字符数组)太过复杂难于掌握,不适合大程序的开发,所以C++标准库定义了一种string类。
C++的字符串与C语言的字符串比较
C语言:char* 是一个指针。
C++:
string是一个类,内部封装了char*,用来管理这个容器。
string类中封装了很多的功能函数,非常实用。例如:find、copy、delete、replace、insert等。
不用考虑内存释放和越界的问题。
string管理char*所分配的内存。每一次string的复制,取值都由string类负责维护,不用担心复制越界和取值越界等。
string容器常用操作
string构造函数
1 2 3 4 string ();string (const string& str);string (const char * s);string (int n, char c);
string基本赋值操作
1 2 3 4 5 6 7 8 string& operator =(const char * s); string& operator =(const string &s); string& operator =(char c); string& assign (const char *s) ;string& assign (const char *s, int n) ;string& assign (const string &s) ;string& assign (int n, char c) ;string& assign (const string &s, int start, int n) ;
string存取字符操作
1 2 char & operator [](int n);char & at (int n)
string拼接操作
1 2 3 4 5 6 7 8 string& operator +=(const string& str); string& operator +=(const char * str); string& operator +=(const char c); string& append (const char *s) ;string& append (const char *s, int n) ;string& append (const string &s) ;string& append (const string &s, int pos, int n) ;string& append (int n, char c) ;
string查找和替换
1 2 3 4 5 6 7 8 9 10 int find (const string& str, int pos = 0 ) const int find (const char * s, int pos = 0 ) const int find (const char * s, int pos, int n) const int find (const char c, int pos = 0 ) const int rfind (const string& str, int pos = npos) const int rfind (const char * s, int pos = npos) const int rfind (const char * s, int pos, int n) const int rfind (const char c, int pos = 0 ) const string& replace (int pos, int n, const string& str) ; string& replace (int pos, int n, const char * s) ;
string比较操作
1 2 3 4 5 6 7 int compare (const string &s) const int compare (const char *s) const
string子串
1 string substr (int pos = 0 , int n = npos) const ;
string插入和删除操作
1 2 3 4 string& insert (int pos, const char * s) ; string& insert (int pos, const string& str) ; string& insert (int pos, int n, char c) ;string& erase (int pos, int n = npos) ;
string和C语言风格字符串转换
1 2 3 4 5 6 string str = "itcast" ; const char * cstr = str.c_str ();char * s = "itcast" ;string str (s) ;
1 2 在c++中存在一个从const char到string的隐式类型转换,却不存在从一个string对象到Cstring的自动类型转换。对于string类型的字符串,可以通过cstr()函数返回string对象对应的C_string. 通常,程序员在整个程序中应坚持使用string类对象,直到必须将内容转化为char时才将其转换为C_string.
提示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 string s = "abcdefg" ; char & a = s[2 ];char & b = s[3 ];a = '1' ; b = '2' ; cout << s << endl; cout << (int *)s.c_str () << endl; s = "pppppppppppppppppppppppp" ; cout << s << endl; cout << (int *)s.c_str () << endl;
vector容器 vector容器基本概念 vector的数据安排以及操作方式,与array非常相似,两者的唯一差别在于空间的运用的灵活性。Array是静态空间,一旦配置了就不能改变,要换大一点或者小一点的空间,可以,一切琐碎得由自己来,首先配置一块新的空间,然后将旧空间的数据搬往新空间,再释放原来的空间。Vector是动态空间,随着元素的加入,它的内部机制会自动扩充空间以容纳新元素。因此vector的运用对于内存的合理利用与运用的灵活性有很大的帮助,我们再也不必害怕空间不足而一开始就要求一个大块头的array了。
vector容器常用操作
vector的构造函数
1 2 3 4 5 6 7 8 vector<T> v; vector (v.begin (), v.end ());vector (n, elem);vector (const vector &vec);int arr[] = {2 ,3 ,4 ,1 ,9 };vector<int > v1 (arr, arr + sizeof (arr) / sizeof (int )) ;
vector的常用赋值函数
1 2 3 4 assign (beg, end);assign (n, elem);vector& operator =(const vector &vec); swap (vec);
vector的大小操作
1 2 3 4 5 6 size ();empty ();resize (int num);resize (int num, elem);capacity ();reserve (int len);
vector的数据存取操作
1 2 3 4 at (int idx); operator [];front ();back ();
vector插入和删除操作
1 2 3 4 5 6 insert (const_iterator pos, int count,ele);push_back (ele); pop_back ();erase (const_iterator start, const_iterator end);erase (const_iterator pos);clear ();
vector迭代器 Vector维护一个线性空间,所以不论元素的型别如何,普通指针都可以作为vector的迭代器,因为vector迭代器所需要的操作行为,如operator, operator->, operator++, operator–, operator+, operator-, operator+=, operator-=, 普通指针天生具备。Vector支持随机存取,而普通指针正有着这样的能力。所以vector提供的是随机访问迭代器(Random Access Iterators).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 vector<int > v; v.push_back (1 ); v.push_back (3 ); v.push_back (5 ); v.push_back (7 ); v.push_back (9 ); for (vector<int >::iterator it = v.begin (); it != v.end (); it++) { cout << *it << endl; } for (vector<int >::iterator it = v.end (); it != v.begin ();) { it--; cout << *it << endl; } for (int & it : v) { cout << it << endl; }
vector小案例
巧用swap收缩内存空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 #include <iostream> #include <vector> using namespace std;int main () vector<int > v; for (int i = 0 ; i < 100000 ;i ++){ v.push_back (i); } cout << "capacity:" << v.capacity () << endl; cout << "size:" << v.size () << endl; v.resize (10 ); cout << "capacity:" << v.capacity () << endl; cout << "size:" << v.size () << endl; vector <int >(v).swap (v); cout << "capacity:" << v.capacity () << endl; cout << "size:" << v.size () << endl; system ("pause" ); return EXIT_SUCCESS; }
reserve预留空间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <vector> using namespace std;int main () vector<int > v; v.reserve (100000 ); int * pStart = NULL ; int count = 0 ; for (int i = 0 ; i < 100000 ;i ++){ v.push_back (i); if (pStart != &v[0 ]){ pStart = &v[0 ]; count++; } } cout << "count:" << count << endl; system ("pause" ); return EXIT_SUCCESS; }
deque容器 deque容器基本概念 Vector容器是单向开口的连续内存空间,deque则是一种双向开口的连续线性空间。所谓的双向开口,意思是可以在头尾两端分别做元素的插入和删除操作,当然,vector容器也可以在头尾两端插入元素,但是在其头部操作效率奇差,无法被接受。
deque容器和vector容器最大的差异,一在于deque允许对头端进行元素的插入和删除操作。二在于deque没有容量的概念,因为它是动态的以分段连续空间组合而成,随时可以增加一段新的空间并链接起来,换句话说,像vector那样,”旧空间不足而重新配置一块更大空间,然后复制元素,再释放旧空间”这样的事情在deque身上是不会发生的。也因此,deque没有必须要提供所谓的空间保留(reserve)功能.
虽然deque容器也提供了Random Access Iterator,但是它的迭代器并不是普通的指针,其复杂度和vector不是一个量级,这当然影响各个运算的层面。因此,除非有必要,我们应该尽可能的使用vector,而不是deque。对deque进行的排序操作,为了最高效率,可将deque先完整的复制到一个vector中,对vector容器进行排序,再复制回deque.
deque容器常用操作
deque构造函数
1 2 3 4 deque<T> deqT; deque (beg, end);deque (n, elem);deque (const deque &deq);
deque赋值操作
1 2 3 4 assign (beg, end);assign (n, elem);deque& operator =(const deque &deq); swap (deq);
deque大小操作
1 2 3 4 deque.size (); deque.empty (); deque.resize (num); deque.resize (num, elem);
deque双端操作和删除
1 2 3 4 push_back (elem);push_front (elem);pop_back ();pop_front ();
deque数据存取
1 2 3 4 at (idx);operator [];front ();back ();
deque插入操作
1 2 3 insert (pos,elem);insert (pos,n,elem);insert (pos,beg,end);
deque删除操作
1 2 3 clear ();erase (beg,end);erase (pos);
deque小案例
有5名选手:选手ABCDE,10个评委分别对每一名选手打分,去除最高分,去除评委中最低分,取平均分。
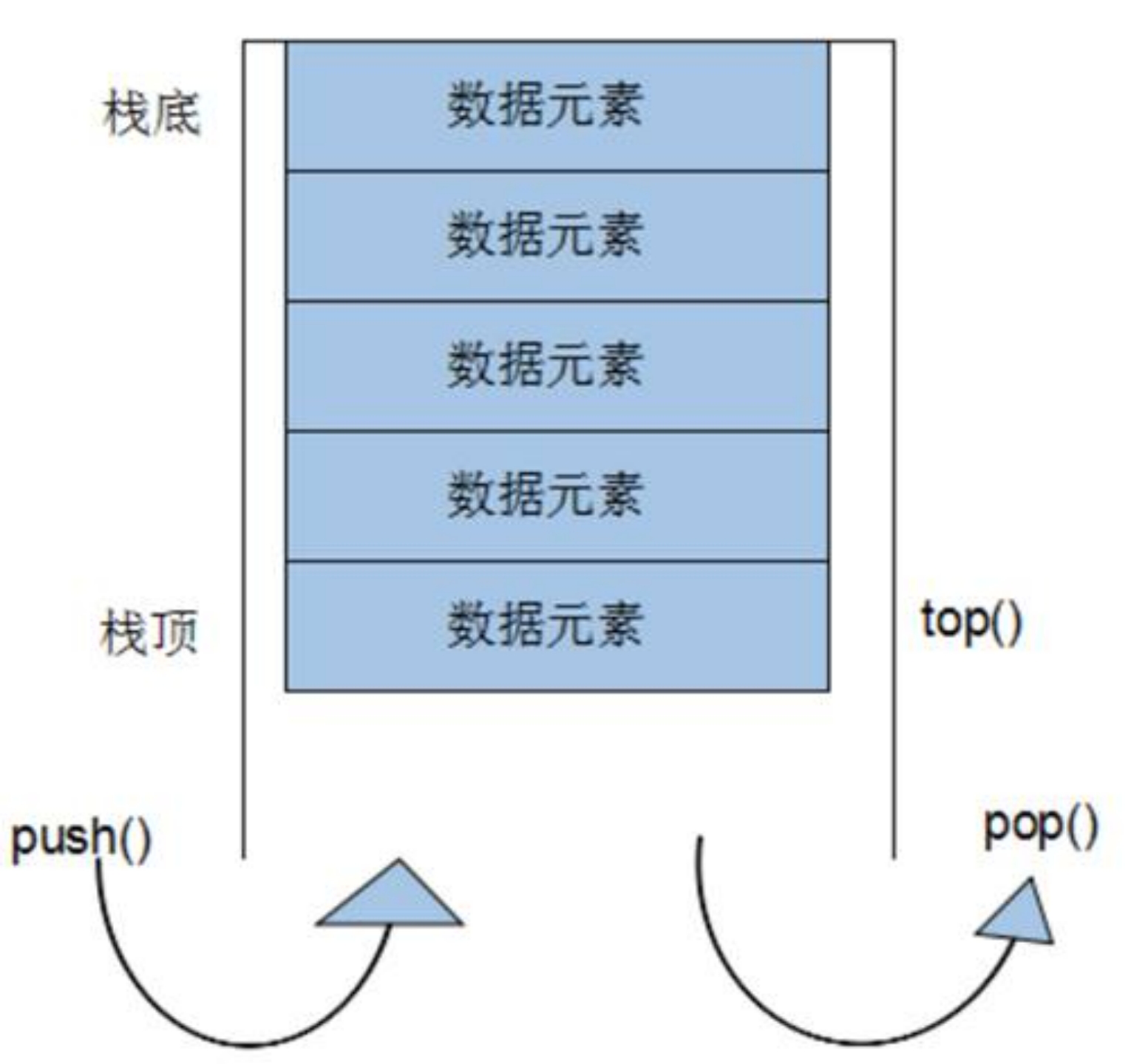
stack容器 stack容器基本概念 stack是一种先进后出(First In Last Out,FILO)的数据结构,它只有一个出口,形式如图所示。stack容器允许新增元素,移除元素,取得栈顶元素,但是除了最顶端外,没有任何其他方法可以存取stack的其他元素。换言之,stack不允许有遍历行为。
stack是没有迭代器的:
Stack所有元素的进出都必须符合”先进后出”的条件,只有stack顶端的元素,才有机会被外界取用。Stack不提供遍历功能,也不提供迭代器。
stack容器常用操作
构造函数
1 2 stack<T> stkT; stack (const stack &stk);
赋值操作
1 stack& operator =(const stack &stk);
数据存取操作
1 2 3 push (elem);pop ();top ();
大小操作
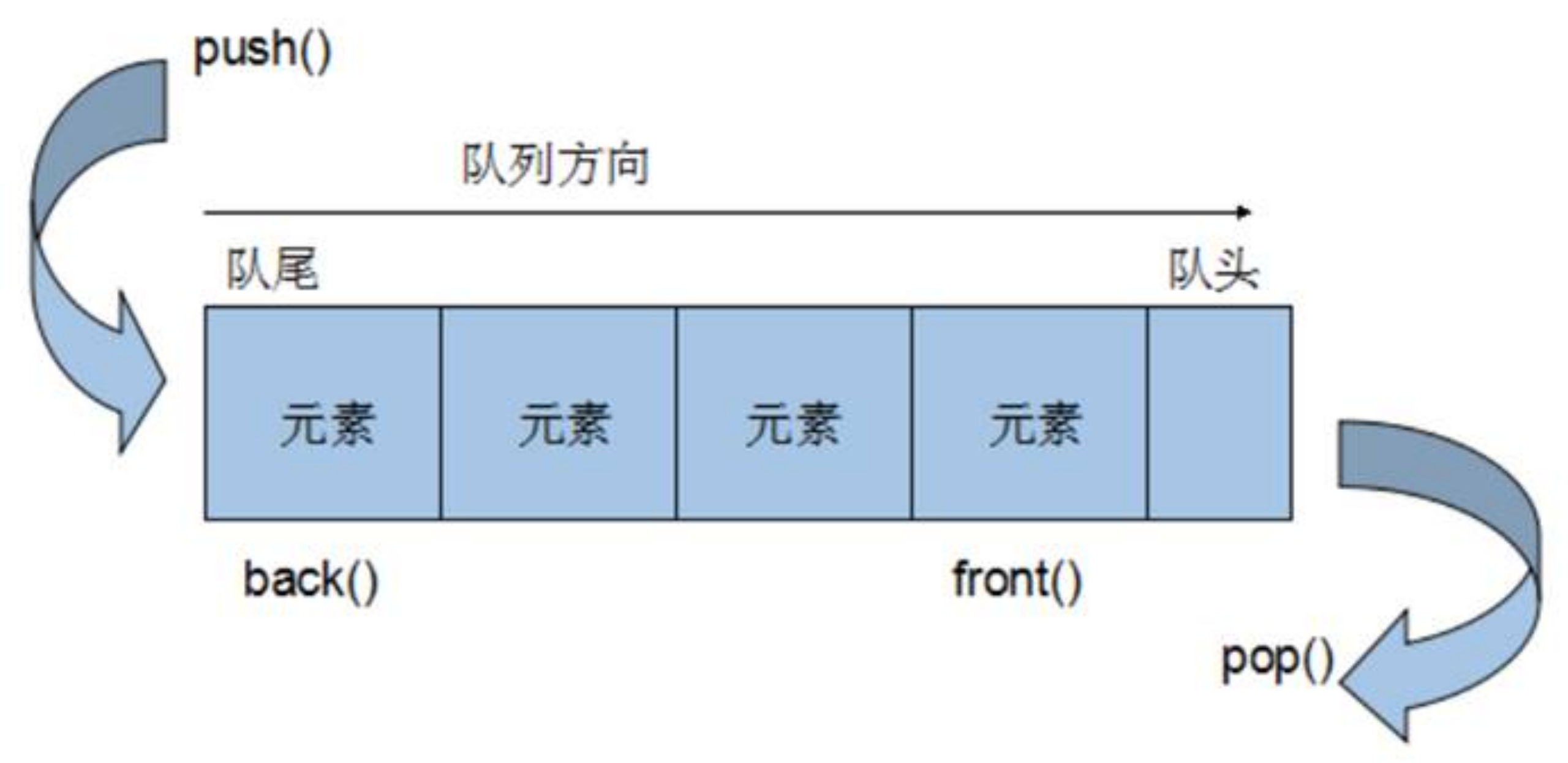
queue容器 queue容器基本概念 Queue是一种先进先出(First In First Out,FIFO)的数据结构,它有两个出口,queue容器允许从一端新增元素,从另一端移除元素。
queue容器没有迭代器:Queue所有元素的进出都必须符合”先进先出”的条件,只有queue的顶端元素,才有机会被外界取用。Queue不提供遍历功能,也不提供迭代器。
queue容器常用操作
构造函数
1 2 queue<T> queT; queue (const queue &que);
存取、插入、删除操作
1 2 3 4 push (elem);pop ();back ();front ();
赋值操作
1 queue& operator =(const queue &que);
大小操作
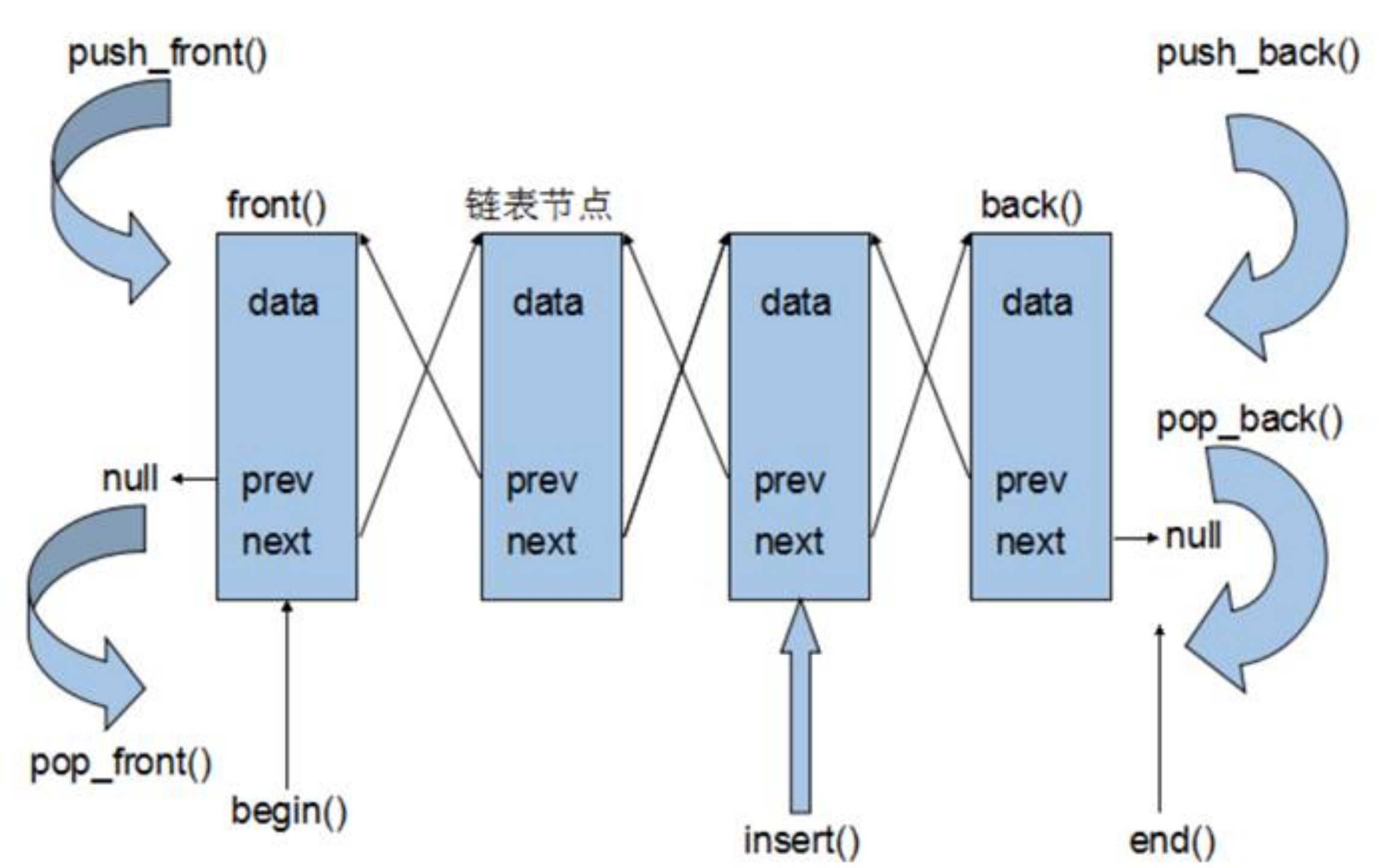
list容器 list容器基本概念 链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
相较于vector的连续线性空间,list就显得复杂许多,它的好处是每次插入或者删除一个元素,就是配置或者释放一个元素的空间。因此,list对于空间的运用有绝对的精准,一点也不浪费。而且,对于任何位置的元素插入或元素的移除,list永远是常数时间。
List和vector是两个最常被使用的容器。
List容器是一个双向链表。
采用动态存储分配,不会造成内存浪费和溢出
链表执行插入和删除操作十分方便,修改指针即可,不需要移动大量元素
链表灵活,但是空间和时间额外耗费较大
list的迭代器 List容器不能像vector一样以普通指针作为迭代器,因为其节点不能保证在同一块连续的内存空间上。List迭代器必须有能力指向list的节点,并有能力进行正确的递增、递减、取值、成员存取操作。所谓”list正确的递增,递减、取值、成员取用”是指,递增时指向下一个节点,递减时指向上一个节点,取值时取的是节点的数据值,成员取用时取的是节点的成员。
由于list是一个双向链表,迭代器必须能够具备前移、后移的能力,所以list容器提供的是Bidirectional Iterators.
list容器常用操作
构造函数
1 2 3 4 list<T> lstT; list (beg,end);list (n,elem);list (const list &lst);
元素插入和删除操作
1 2 3 4 5 6 7 8 9 10 11 push_back (elem);pop_back ();push_front (elem);pop_front ();insert (pos,elem);insert (pos,n,elem);insert (pos,beg,end);clear ();erase (beg,end);erase (pos);remove (elem);
大小操作
1 2 3 4 5 6 7 8 9 size ();empty ();resize (num);resize (num, elem);
赋值操作
1 2 3 4 assign (beg, end);assign (n, elem);list& operator =(const list &lst); swap (lst);
数据存取操作
反转、排序
set/multiset容器 set/multiset容器基本概念 Set的特性是。所有元素都会根据元素的值自动被排序。Set不允许两个元素有相同的值。
我们可以通过set的迭代器改变set元素的值吗?不行,因为set元素值就是其值,关系到set元素的排序规则。如果任意改变set元素值,会严重破坏set组织。换句话说,set的iterator是一种const_iterator.
set拥有和list某些相同的性质,当对容器中的元素进行插入操作或者删除操作的时候,操作之前所有的迭代器,在操作完成之后依然有效,被删除的那个元素的迭代器必然是一个例外。
multiset特性及用法和set完全相同,唯一的差别在于它允许值重复。set和multiset的底层实现是红黑树,红黑树为平衡二叉树的一种。
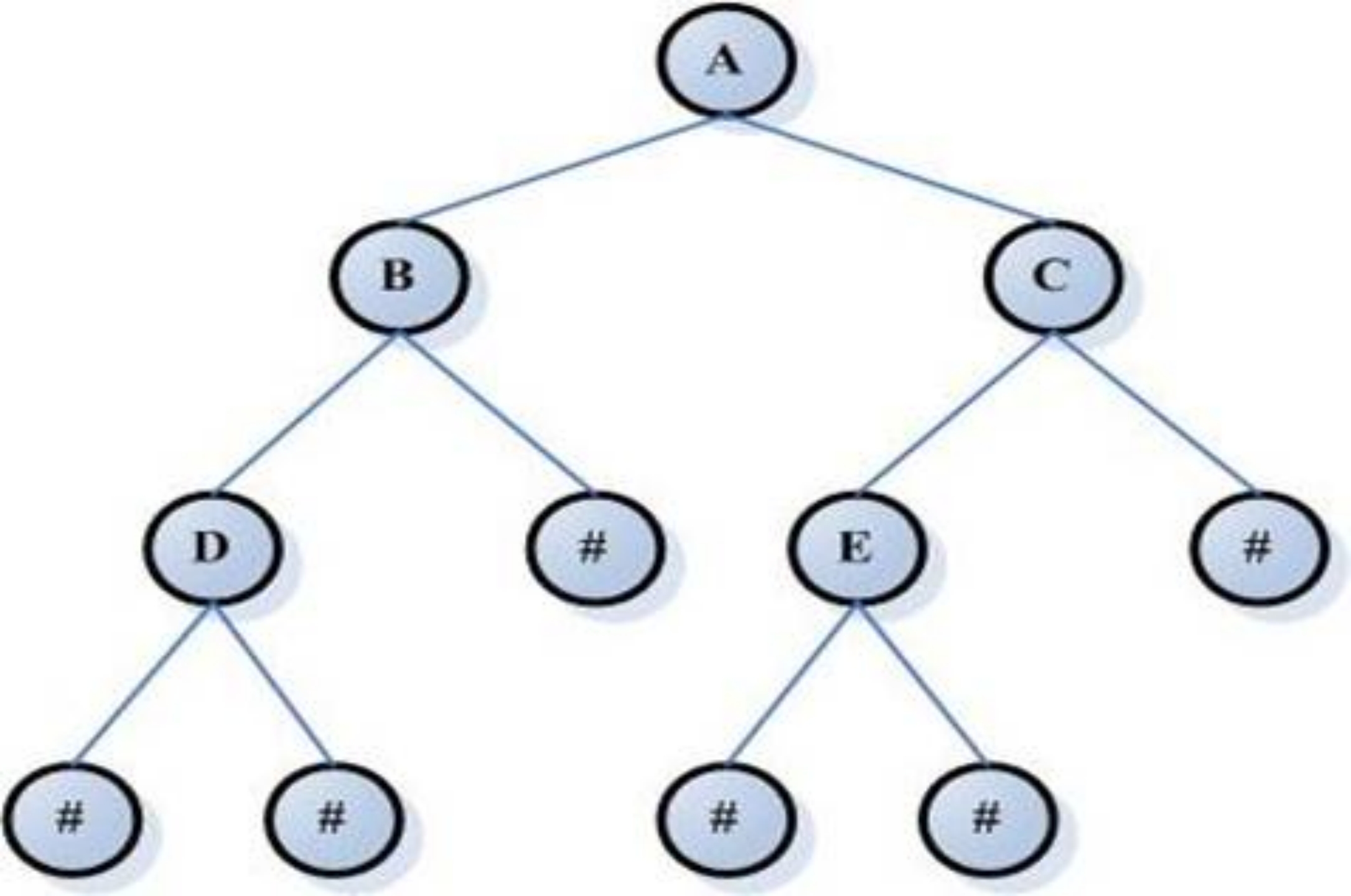
树的简单知识:
二叉树就是任何节点最多只允许有两个字节点。分别是左子结点和右子节点
二叉树示意图
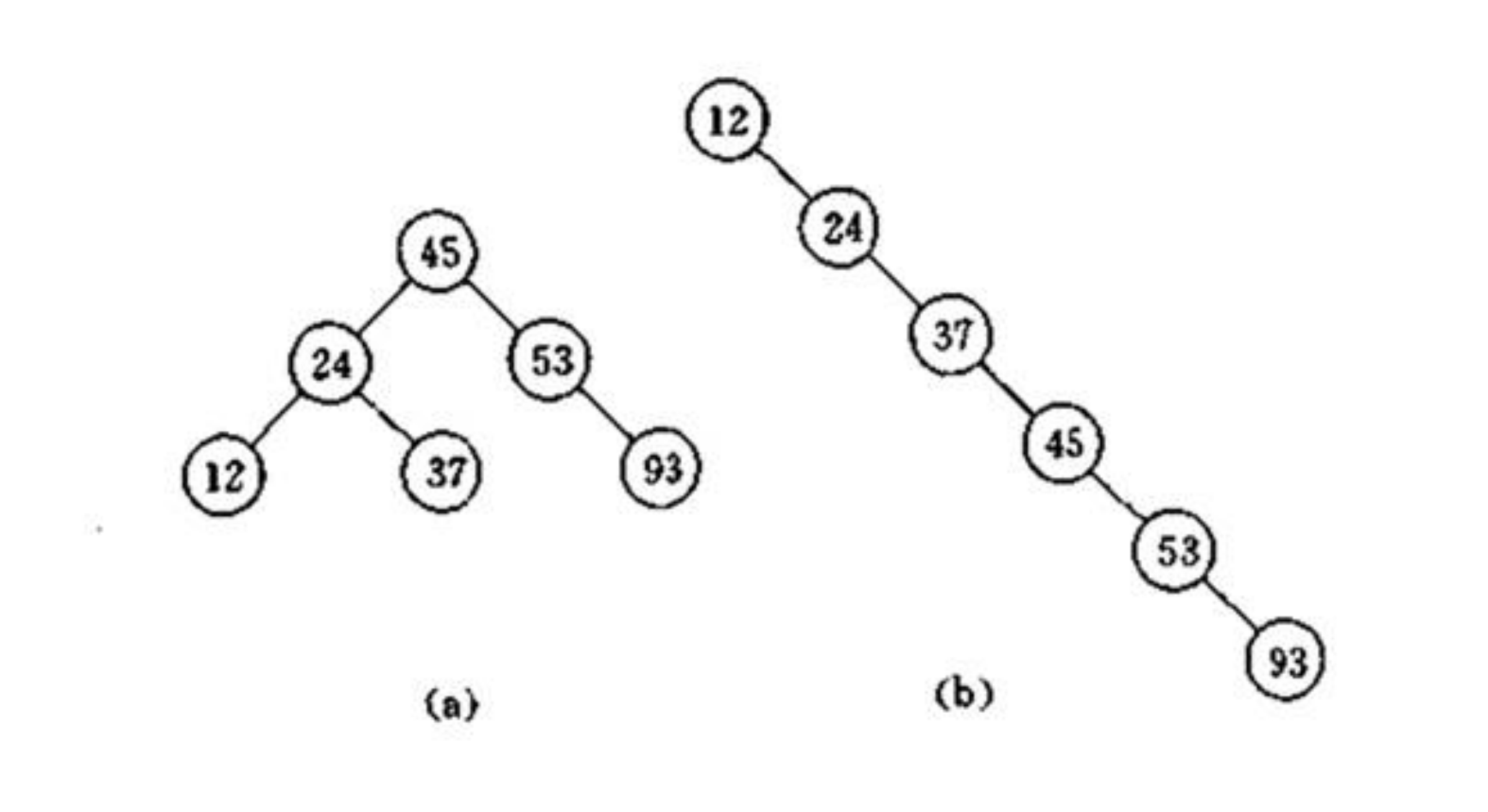
二叉搜索树,是指二叉树中的节点按照一定的规则进行排序,使得对二叉树中元素访问更加高效。二叉搜索树的放置规则是:任何节点的元素值一定大于其左子树中的每一个节点的元素值,并且小于其右子树的值。因此从根节点一直向左走,一直到无路可走,即得到最小值,一直向右走,直至无路可走,可得到最大值。那么在二叉搜索树中找到最大元素和最小元素是非常简单的事情。下图为二叉搜索树:
上面我们介绍了二叉搜索树,那么当一个二叉搜索树的左子树和右子树不平衡的时候,那么搜索依据上图表示,搜索9所花费的时间要比搜索17所花费的时间要多,由于我们的输入或者经过我们插入或者删除操作,二叉树失去平衡,造成搜索效率降低。
set/multiset容器常用操作
构造函数
1 2 3 set<T> st; mulitset<T> mst; set (const set &st);
set赋值
1 2 set& operator =(const set &st); swap (st);
set大小操作
插入和删除操作
1 2 3 4 5 insert (elem);clear ();erase (pos);erase (beg, end);erase (elem);
查找操作
1 2 3 4 5 find (key);count (key);lower_bound (keyElem);upper_bound (keyElem);equal_range (keyElem);
对组 对组(pair)将一对值组合成一个值,这一对值可以具有不同的数据类型,两个值可以分别用pair的两个公有属性first和second访问。
类模板:template <class T1, class T2> struct pair.
如何创建对组?
1 2 3 4 5 6 7 8 9 10 11 12 pair<string, int > pair1 (string("name" ), 20 ) ;cout << pair1.first << endl; cout << pair1.second << endl; pair<string, int > pair2 = make_pair ("name" , 30 ); cout << pair2.first << endl; cout << pair2.second << endl; pair<string, int > pair3 = pair2; cout << pair3.first << endl; cout << pair3.second << endl;
map/multimap容器 map/multimap基本概念 Map的特性是,所有元素都会根据元素的键值自动排序。Map所有的元素都是pair,同时拥有实值和键值,pair的第一元素被视为键值,第二元素被视为实值,map不允许两个元素有相同的键值。
我们可以通过map的迭代器改变map的键值吗?答案是不行,因为map的键值关系到map元素的排列规则,任意改变map键值将会严重破坏map组织。如果想要修改元素的实值,那么是可以的。
Map和list拥有相同的某些性质,当对它的容器元素进行新增操作或者删除操作时,操作之前的所有迭代器,在操作完成之后依然有效,当然被删除的那个元素的迭代器必然是个例外。
Multimap和map的操作类似,唯一区别multimap键值可重复。
Map和multimap都是以红黑树为底层实现机制。
map/multimap常用操作
构造函数
1 2 map<T1, T2> mapTT; map (const map &mp);
赋值操作
1 2 map& operator =(const map &mp); swap (mp);
大小操作
插入操作
1 2 3 4 5 6 7 8 9 10 11 map.insert (...); map<int , string> mapStu; mapStu.insert (pair <int , string>(3 , "小张" )); mapStu.inset (make_pair (-1 , "校长" )); mapStu.insert (map<int , string>::value_type (1 , "小李" )); mapStu[3 ] = "小刘" ; mapStu[5 ] = "小王" ;
删除元素
1 2 3 4 clear ();erase (pos);erase (beg,end);erase (keyElem);
查找操作
1 2 3 4 5 find (key);count (keyElem);lower_bound (keyElem);upper_bound (keyElem);equal_range (keyElem);
multimap案例 公司今天招聘了5个员工,5名员工进入公司之后,需要指派员工在那个部门工作
人员信息有: 姓名 年龄 电话 工资等组成
通过Multimap进行信息的插入 保存 显示
分部门显示员工信息 显示全部员工信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 #include <iostream> #include <map> #include <string> #include <vector> using namespace std;#define SALE_DEPATMENT 1 #define DEVELOP_DEPATMENT 2 #define FINACIAL_DEPATMENT 3 #define ALL_DEPATMENT 4 class person {public : string name; int age; double salary; string tele; }; void CreatePerson (vector<person>& vlist) string seed = "ABCDE" ; for (int i = 0 ; i < 5 ; i++){ person p; p.name = "员工" ; p.name += seed[i]; p.age = rand () % 30 + 20 ; p.salary = rand () % 20000 + 10000 ; p.tele = "010-8888888" ; vlist.push_back (p); } } void PersonByGroup (vector<person>& vlist, multimap<int , person>& plist) int operate = -1 ; for (vector<person>::iterator it = vlist.begin (); it != vlist.end (); it++){ cout << "当前员工信息:" << endl; cout << "姓名:" << it->name << " 年龄:" << it->age << " 工资:" << it->salary << " 电话:" << it->tele << endl; cout << "请对该员工进行部门分配(1 销售部门, 2 研发部门, 3 财务部门):" << endl; scanf ("%d" , &operate); while (true ){ if (operate == SALE_DEPATMENT){ plist.insert (make_pair (SALE_DEPATMENT, *it)); break ; } else if (operate == DEVELOP_DEPATMENT){ plist.insert (make_pair (DEVELOP_DEPATMENT, *it)); break ; } else if (operate == FINACIAL_DEPATMENT){ plist.insert (make_pair (FINACIAL_DEPATMENT, *it)); break ; } else { cout << "您的输入有误,请重新输入(1 销售部门, 2 研发部门, 3 财务部门):" << endl; scanf ("%d" , &operate); } } } cout << "员工部门分配完毕!" << endl; cout << "***********************************************************" << endl; } void printList (multimap<int , person>& plist, int myoperate) if (myoperate == ALL_DEPATMENT){ for (multimap<int , person>::iterator it = plist.begin (); it != plist.end (); it++){ cout << "姓名:" << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << " 电话:" << it->second.tele << endl; } return ; } multimap<int , person>::iterator it = plist.find (myoperate); int depatCount = plist.count (myoperate); int num = 0 ; if (it != plist.end ()){ while (it != plist.end () && num < depatCount){ cout << "姓名:" << it->second.name << " 年龄:" << it->second.age << " 工资:" << it->second.salary << " 电话:" << it->second.tele << endl; it++; num++; } } } void ShowPersonList (multimap<int , person>& plist, int myoperate) switch (myoperate) { case SALE_DEPATMENT: printList (plist, SALE_DEPATMENT); break ; case DEVELOP_DEPATMENT: printList (plist, DEVELOP_DEPATMENT); break ; case FINACIAL_DEPATMENT: printList (plist, FINACIAL_DEPATMENT); break ; case ALL_DEPATMENT: printList (plist, ALL_DEPATMENT); break ; } } void PersonMenue (multimap<int , person>& plist) int flag = -1 ; int isexit = 0 ; while (true ){ cout << "请输入您的操作((1 销售部门, 2 研发部门, 3 财务部门, 4 所有部门, 0退出):" << endl; scanf ("%d" , &flag); switch (flag) { case SALE_DEPATMENT: ShowPersonList (plist, SALE_DEPATMENT); break ; case DEVELOP_DEPATMENT: ShowPersonList (plist, DEVELOP_DEPATMENT); break ; case FINACIAL_DEPATMENT: ShowPersonList (plist, FINACIAL_DEPATMENT); break ; case ALL_DEPATMENT: ShowPersonList (plist, ALL_DEPATMENT); break ; case 0 : isexit = 1 ; break ; default : cout << "您的输入有误,请重新输入!" << endl; break ; } if (isexit == 1 ){ break ; } } } int main () vector<person> vlist; multimap<int , person> plist; CreatePerson (vlist); PersonByGroup (vlist, plist); PersonMenue (plist); system ("pause" ); return EXIT_SUCCESS; }
算法 函数对象 重载函数调用操作符的类,其对象常称为函数对象(function object),即它们是行为类似函数的对象,也叫仿函数(functor),其实就是重载“()”操作符,使得类对象可以像函数那样调用。
注意:
1.函数对象(仿函数)是一个类,不是一个函数。
2.函数对象(仿函数)重载了”() ”操作符使得它可以像函数一样调用。
分类:假定某个类有一个重载的operator(),而且重载的operator()要求获取一个参数,我们就将这个类称为“一元仿函数”(unary functor);相反,如果重载的operator()要求获取两个参数,就将这个类称为“二元仿函数”(binary functor)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class MyPrint { public : MyPrint () { m_Num = 0 ; } int m_Num; public : void operator () (int num) { cout << num << endl; m_Num++; } }; void test01 () MyPrint myPrint; myPrint (20 ); } void test02 () MyPrint myPrint; myPrint (20 ); myPrint (20 ); myPrint (20 ); cout << myPrint.m_Num << endl; } void doBusiness (MyPrint print,int num) print (num); } void test03 () doBusiness (MyPrint (),30 ); }
谓语 谓词是指普通函数或重载的operator()返回值是bool类型的函数对象(仿函数)。如果operator接受一个参数,那么叫做一元谓词,如果接受两个参数,那么叫做二元谓词,谓词可作为一个判断式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 class GreaterThenFive { public : bool operator () (int num) { return num > 5 ; } }; void test01 () vector<int > v; for (int i = 0 ; i < 10 ;i ++) { v.push_back (i); } vector<int >::iterator it = find_if (v.begin (), v.end (), GreaterThenFive ()); if (it == v.end ()) { cout << "没有找到" << endl; } else { cout << "找到了: " << *it << endl; } } class MyCompare { public : bool operator () (int num1, int num2) { return num1 > num2; } }; void test02 () vector<int > v; v.push_back (10 ); v.push_back (40 ); v.push_back (20 ); v.push_back (90 ); v.push_back (60 ); sort (v.begin (), v.end ()); for (vector<int >::iterator it = v.begin (); it != v.end ();it++) { cout << *it << " " ; } cout << endl; cout << "----------------------------" << endl; sort (v.begin (), v.end (),MyCompare ()); for (vector<int >::iterator it = v.begin (); it != v.end (); it++) { cout << *it << " " ; } cout << endl; }
内建函数对象 STL内建了一些函数对象。分为:算数类函数对象,关系运算类函数对象,逻辑运算类仿函数。这些仿函数所产生的对象,用法和一般函数完全相同,当然我们还可以产生无名的临时对象来履行函数功能。使用内建函数对象,需要引入头文件 #include。
6个算数类函数对象,除了negate是一元运算,其他都是二元运算。
template *class* * T> T plus**//加法仿函数 template* *class* * T> T minus**//减法仿函数 template* *class* * T> T multiplies**//乘法仿函数 *template* *class* * T> T divides**//除法仿函数 *template* *class* * T> T modulus**//取模仿函数 *template* *class* * T> T negate**//取反仿函数
6个关系运算类函数对象,每一种都是二元运算。
*template* *class* * T> bool equal_to**//等于 *template* *class* * T> bool not_equal_to**//不等于 *template* *class* * T> bool greater**//大于 *template* *class* * T> bool greater_equal**//大于等于 *template* *class* * T> bool less**//小于 *template* *class* * T> bool less_equal**//小于等于
逻辑运算类运算函数,not为一元运算,其余为二元运算。
*template* *class* * T> bool logical_and**//逻辑与 *template* *class* * T> bool logical_or**//逻辑或 *template* *class* * T> bool logical_not**//逻辑非
内建函数对象举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 void test01 () negate<int > n; cout << n (50 ) << endl; } void test02 () plus<int > p; cout << p (10 , 20 ) << endl; } void test03 () vector<int > v; srand ((unsigned int )time (NULL )); for (int i = 0 ; i < 10 ; i++){ v.push_back (rand () % 100 ); } for (vector<int >::iterator it = v.begin (); it != v.end (); it++){ cout << *it << " " ; } cout << endl; sort (v.begin (), v.end (), greater <int >()); for (vector<int >::iterator it = v.begin (); it != v.end (); it++){ cout << *it << " " ; } cout << endl; }
函数对象适配器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 class MyPrint :public binary_function<int ,int ,void >{ public : void operator () (int v1,int v2) const { cout << "v1 = : " << v1 << " v2 = :" <<v2 << " v1+v2 = :" << (v1 + v2) << endl; } }; void test01 () vector<int >v; for (int i = 0 ; i < 10 ; i++) { v.push_back (i); } cout << "请输入起始值:" << endl; int x; cin >> x; for_each(v.begin (), v.end (), bind1st (MyPrint (), x)); } class GreaterThenFive :public unary_function<int ,bool >{ public : bool operator () (int v) const { return v > 5 ; } }; void test02 () vector <int > v; for (int i = 0 ; i < 10 ;i++) { v.push_back (i); } vector<int >::iterator it = find_if (v.begin (), v.end (), not1 ( bind2nd (greater <int >(),5 ))); if (it == v.end ()) { cout << "没找到" << endl; } else { cout << "找到" << *it << endl; } sort (v.begin (), v.end (), not2 (less <int >())); for_each(v.begin (), v.end (), [](int val){cout << val << " " ; }); } void MyPrint03 (int v,int v2) cout << v + v2<< " " ; } void test03 () vector <int > v; for (int i = 0 ; i < 10 ; i++) { v.push_back (i); } for_each(v.begin (), v.end (), bind2nd ( ptr_fun ( MyPrint03 ), 100 )); } class Person { public : Person (string name, int age) { m_Name = name; m_Age = age; } void ShowPerson () cout << "成员函数:" << "Name:" << m_Name << " Age:" << m_Age << endl; } void Plus100 () { m_Age += 100 ; } public : string m_Name; int m_Age; }; void MyPrint04 (Person &p) cout << "姓名:" << p.m_Name << " 年龄:" << p.m_Age << endl; }; void test04 () vector <Person>v; Person p1 ("aaa" , 10 ) ; Person p2 ("bbb" , 20 ) ; Person p3 ("ccc" , 30 ) ; Person p4 ("ddd" , 40 ) ; v.push_back (p1); v.push_back (p2); v.push_back (p3); v.push_back (p4); for_each(v.begin (), v.end (), mem_fun_ref (&Person::ShowPerson)); } void test05 () vector<Person*> v1; Person p1 ("aaa" , 10 ) ; Person p2 ("bbb" , 20 ) ; Person p3 ("ccc" , 30 ) ; Person p4 ("ddd" , 40 ) ; v1.push_back (&p1); v1.push_back (&p2); v1.push_back (&p3); v1.push_back (&p4); for_each(v1.begin (), v1.end (), mem_fun (&Person::ShowPerson)); }
算法概述 算法主要是由头文件组成。
是所有STL头文件中最大的一个,其中常用的功能涉及到比较,交换,查找,遍历,复制,修改,反转,排序,合并等…
体积很小,只包括在几个序列容器上进行的简单运算的模板函数.
定义了一些模板类,用以声明函数对象。
常用遍历算法 for_each遍历算法 1 2 3 4 5 6 7 8 for_each(iterator beg, iterator end, _callback);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 void print01 (int val) cout << val << " " ; } struct print001 { void operator () (int val) cout << val << " " ; } }; void test01 () vector<int > v; for (int i = 0 ; i < 10 ;i++){ v.push_back (i); } for_each(v.begin (), v.end (), print01); cout << endl; for_each(v.begin (), v.end (), print001 ()); cout << endl; } struct print02 { print02 (){ mCount = 0 ; } void operator () (int val) cout << val << " " ; mCount++; } int mCount; }; void test02 () vector<int > v; for (int i = 0 ; i < 10 ; i++){ v.push_back (i); } print02 p = for_each(v.begin (), v.end (), print02 ()); cout << endl; cout << p.mCount << endl; } struct print03 : public binary_function<int , int , void >{ void operator () (int val,int bindParam) const cout << val + bindParam << " " ; } }; void test03 () vector<int > v; for (int i = 0 ; i < 10 ; i++){ v.push_back (i); } for_each(v.begin (), v.end (), bind2nd (print03 (),100 )); }
1 2 3 4 5 6 7 8 9 10 transform (iterator beg1, iterator end1, iterator beg2, _callbakc);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 struct transformTest01 { int operator () (int val) return val + 100 ; } }; struct print01 { void operator () (int val) cout << val << " " ; } }; void test01 () vector<int > vSource; for (int i = 0 ; i < 10 ;i ++){ vSource.push_back (i + 1 ); } vector<int > vTarget; vTarget.resize (vSource.size ()); vector<int >::iterator it = transform (vSource.begin (), vSource.end (), vTarget.begin (), transformTest01 ()); for_each(vTarget.begin (), vTarget.end (), print01 ()); cout << endl; } struct transformTest02 { int operator () (int v1,int v2) return v1 + v2; } }; void test02 () vector<int > vSource1; vector<int > vSource2; for (int i = 0 ; i < 10 ; i++){ vSource1.push_back (i + 1 ); } vector<int > vTarget; vTarget.resize (vSource1.size ()); transform (vSource1.begin (), vSource1.end (), vSource2.begin (),vTarget.begin (), transformTest02 ()); for_each(vTarget.begin (), vTarget.end (), print01 ()); cout << endl; }
常用查找算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 find (iterator beg, iterator end, value)find_if (iterator beg, iterator end, _callback);adjacent_find (iterator beg, iterator end, _callback);bool binary_search (iterator beg, iterator end, value) count (iterator beg, iterator end, value);count_if (iterator beg, iterator end, _callback);
常用排序算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 merge (iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)sort (iterator beg, iterator end, _callback)random_shuffle (iterator beg, iterator end)reverse (iterator beg, iterator end)
常用拷贝和替换算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 copy (iterator beg, iterator end, iterator dest)replace (iterator beg, iterator end, oldvalue, newvalue)replace_if (iterator beg, iterator end, _callback, newvalue)swap (container c1, container c2)
常用算数生成算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 accumulate (iterator beg, iterator end, value)fill (iterator beg, iterator end, value)
常用集合算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 set_intersection (iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)set_union (iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)set_difference (iterator beg1, iterator end1, iterator beg2, iterator end2, iterator dest)